決策樹原理
介紹
用一句話代表決策樹我認為是他是白盒子AI,以往的AI都是只有輸入與輸出,中間怎麼運作的,也都難以了解,但決策樹會把中間的過程顯示出來,因此,可以讓使用的人更對機器學習所得到的結果更有把握度。
什麼是決策樹?
決策樹(Decision Tree)是一種基於樹狀結構的模型,可用於分類或回歸的問題。
每個節點會有條件判斷,依據不同的條件,分出不同結果,顯示在下一個子節點,最終到達葉節點,就可以得到最終的分類結果或預測值。
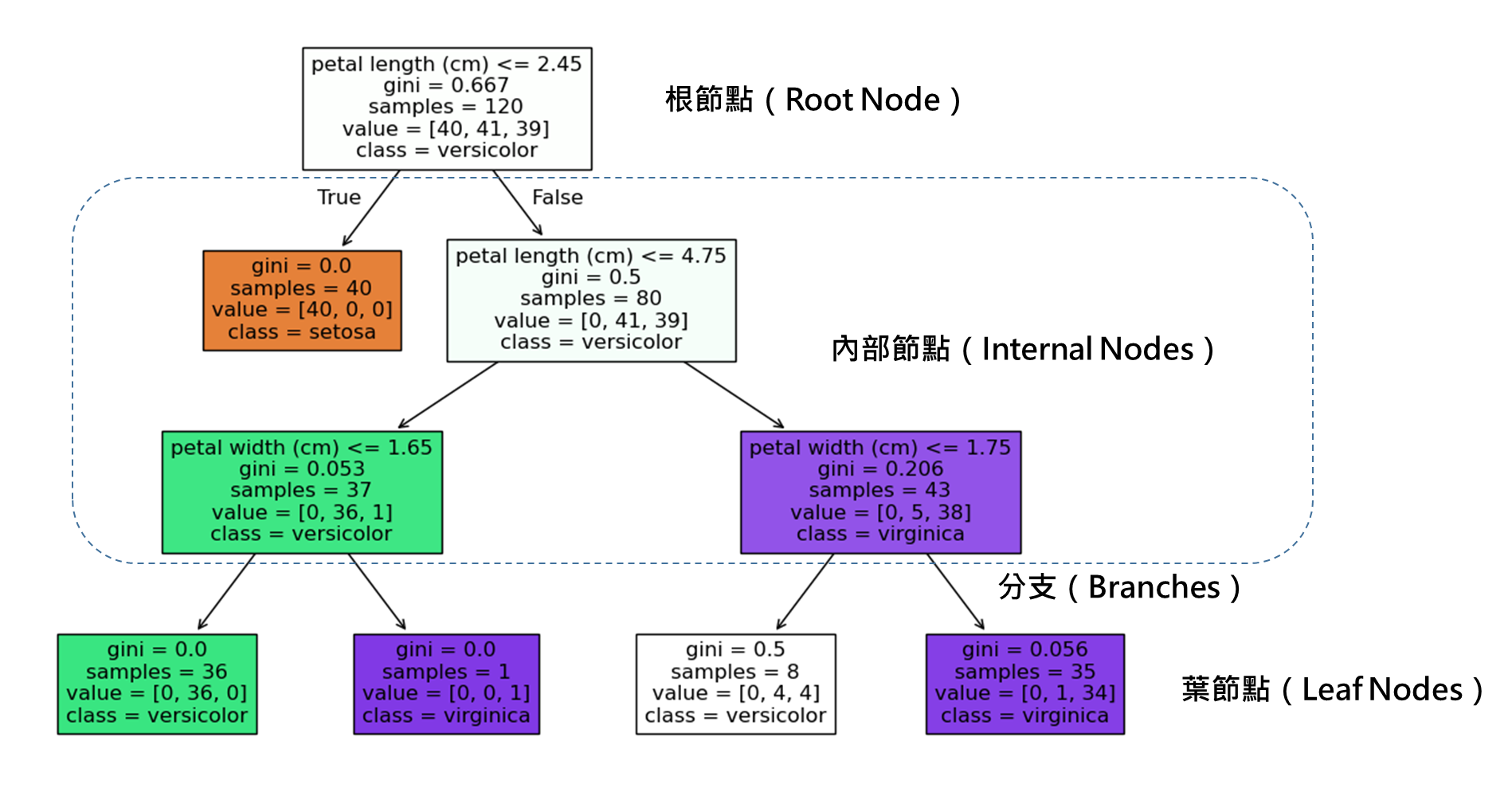
下方為決策樹整體的結構,可以看到會從上往下分枝,最上方只有一個點,最下方會越分越多的分枝。
決策樹的主要特點就是易於理解和解釋: 由於他可以顯示分枝的過程,條件都很透明化,可以讓使用者好理解,有更高的把握度,也可以比較容易解釋給別人了解。
決策樹結構
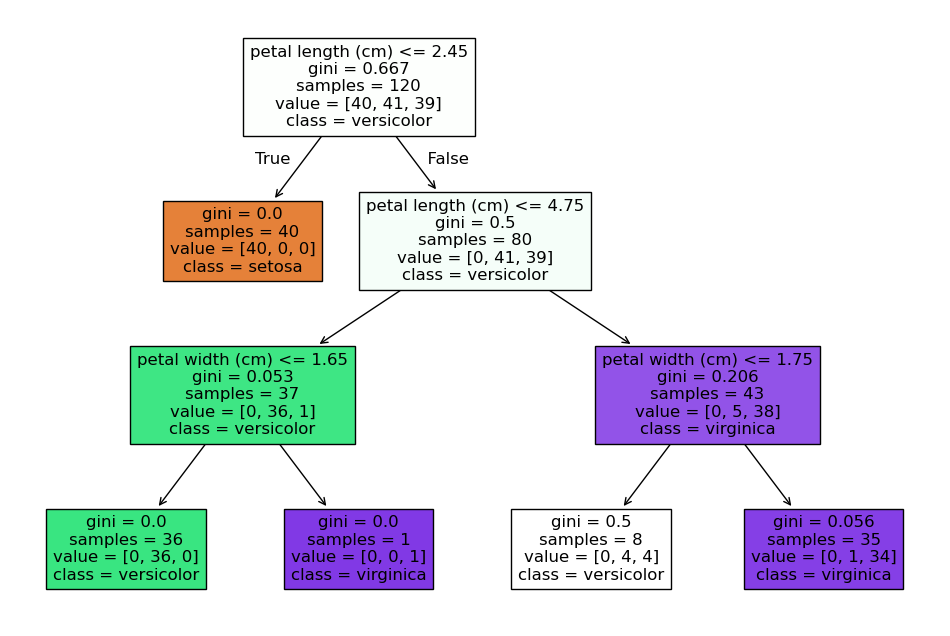
決策樹的結構主要由以下幾個部分組成:
- 根節點(Root Node):決策樹的起點。
- 內部節點(Internal Nodes):根據不同的條件對數據進行拆分。
- 葉節點(Leaf Nodes):表示最終的分類或預測結果。
- 分支(Branches):連接節點之間的線,表示數據的流向。
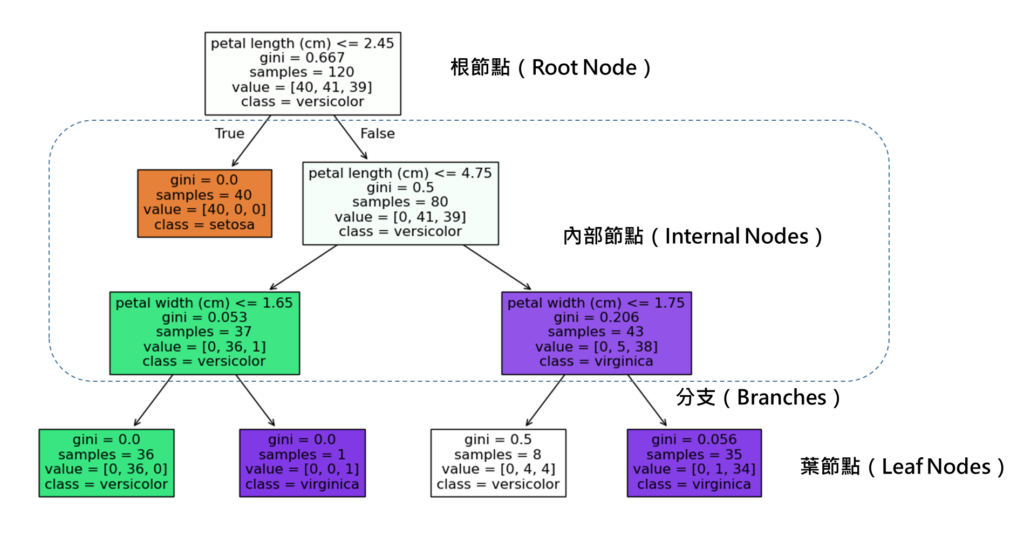
建立法則
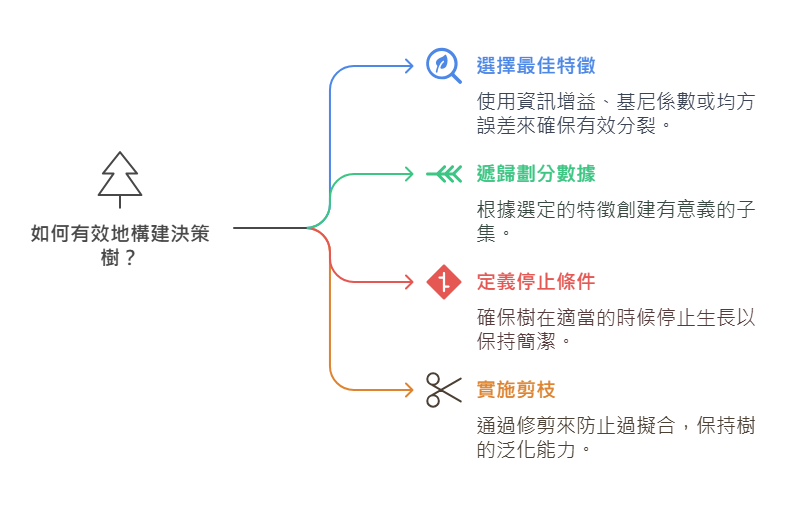
建立決策樹時,會有以下步驟:
- 選擇最佳特徵作為分枝的標準,常使用的指標有資訊增益(Information Gain)、吉尼係數(Gini Index)或均方誤差(MSE)等標準來選擇最佳的特徵。
- 遞歸劃分數據:依據選定的特徵,將數據集分割為不同的子集。
- 停止條件:當所有數據屬於同一類別、達到最大深度或無法進一步劃分時,停止劃分。
- 剪枝(Pruning):為了避免過擬合,可以透過預剪枝(Pre-Pruning)或後剪枝(Post-Pruning)來修剪決策樹。
優缺比較
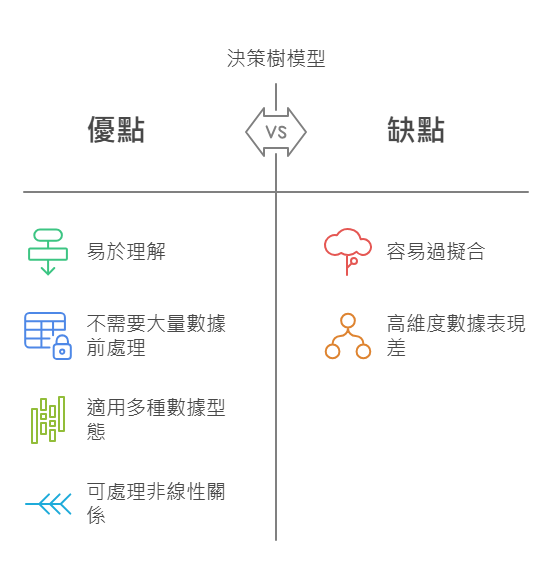
決策樹的優點與缺點分別有
優點:
- 易於理解與解釋,讓人直觀解讀輸出結果。
- 不需要大量的數據前處理,可處理缺失值。
- 適用在數值預測與分類問題上。
- 可處理非線性複雜的分類問題上。
缺點:
- 容易過擬合。
- 對於高維度數據可能表現不佳,可能導致樹變得過於複雜。
決策樹的延伸應用
後續也有許多開發者,發展整體學習方法,就是基於決策樹原理延伸發展,進而提升決策樹的準確度與穩健性。像是有隨機森林,梯度提升機,XGBoost,LightGBM等等,效果也是非常顯著,也有不少人應用這些技術在機器學習的比賽上。
結論
決策樹我認為是一個機器學習當中,特別的一項技術,也是後面大家發展整體學習的一個基石,它的原理也是需要被廣為了解。
想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。