為什麼「注意力」是 AI 的最強超能力?
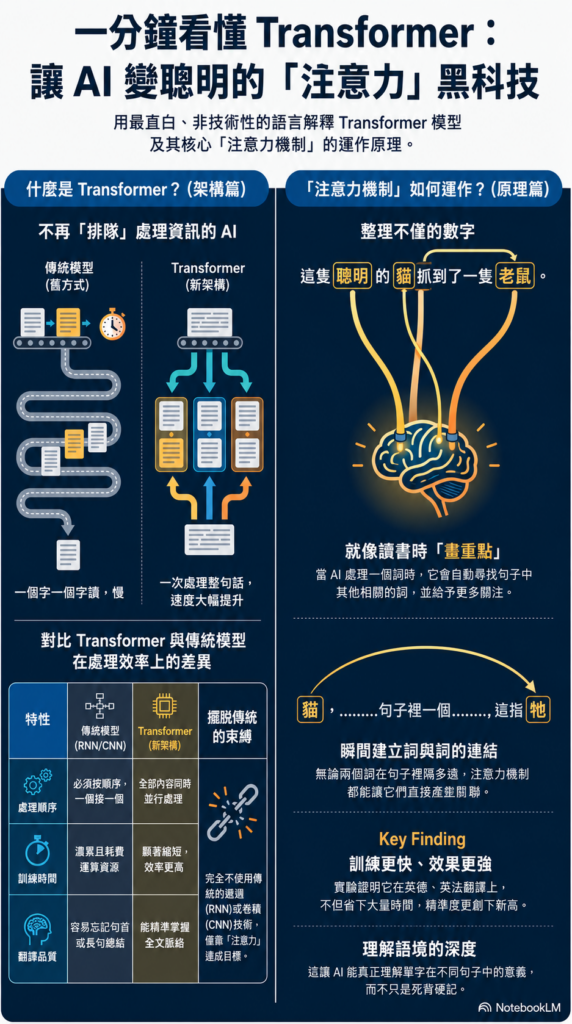
傳統的 RNN 在分析句子時,會從頭到尾逐字閱讀。這樣的設計有一個根本的問題:句子越長,越早出現的資訊就越容易被遺忘,模型到了句尾,往往已經難以回憶起開頭的內容。
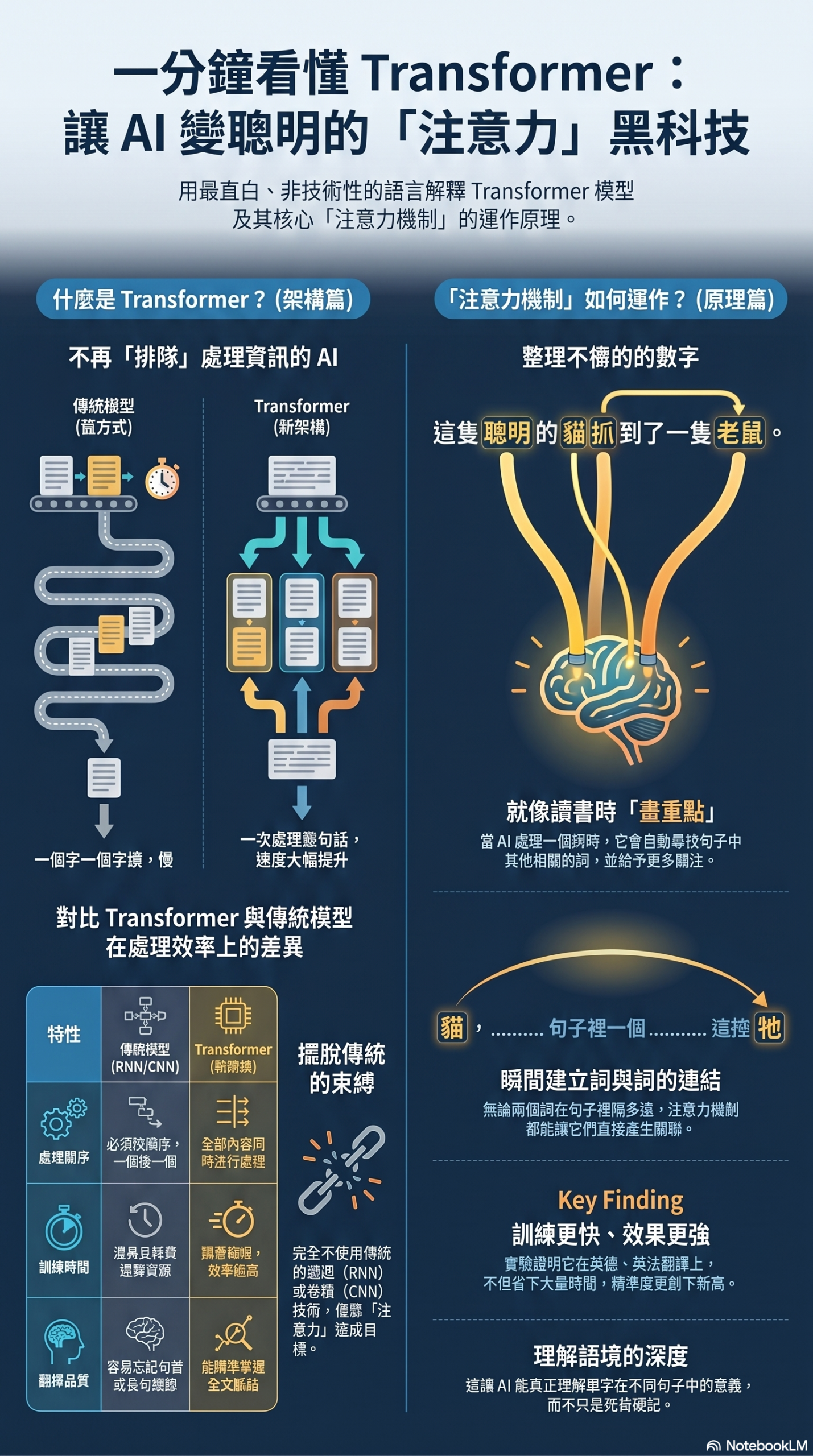
Attention(注意力機制)的核心概念,正是為了解決這個限制而生。它讓模型在理解某個字詞時,能夠同時參考句子中所有其他字詞,並判斷彼此之間的關聯程度,進而更全面地掌握語句的含義。
一個直觀的例子
「貓追老鼠,因為牠很餓。」
當模型讀到「牠」時,需要判斷「牠」究竟指的是誰。Attention 機制會計算「牠」與句中每個字的關聯強度:
- 「牠」與「貓」→ 關聯高
- 「牠」與「老鼠」→ 關聯低
因此,模型能夠推斷「牠」指的是貓,而不是老鼠。
RNN vs. Attention:直觀比較
| RNN | Attention | |
|---|---|---|
| 閱讀方式 | 逐字依序讀取 | 同時看見整句 |
| 遠距資訊 | 容易遺忘 | 可直接參考 |
| 字詞關係 | 隱含在隱藏狀態中 | 明確計算關聯強度 |
更多關聯的例子
| 字詞 | 最關注的對象 |
|---|---|
| 牠 | 貓 |
| 吃 | 蘋果 |
| 台北 | 台灣 |
透過這種方式,模型不再受限於「讀到哪、記到哪」的線性限制,而是能夠在整個句子的範圍內,自由地建立字詞之間的關聯。這讓 AI 對語句的理解更加深入,也是 Transformer 架構能夠大幅超越傳統 RNN 的關鍵原因之一。