大型語言模型(large language model, LLM) :微調技巧(fine-tuning)
李彼德的 AI 學習地圖
- 新手必讀: [AI 學習路線圖]|[監督式學習六步驟]
- 核心原理: [什麼是 DNN?] → [Attention 機制] → [Transformer 原理] → [BERT 模型]
- 實作工具: [Gemini 教學]|[Anaconda 安裝]|[Colab 教學]
為什麼要介紹大型語言模型(large language model, LLM)以及微調的技巧(fine-tuning)?
近來最有感的AI應用就是OpenAI開發的ChatGPT,這是因為只需要利用自然語言的溝通就可讓ChatGPT產生滿足大家的需求,所以讓大家在使用上覺得受到幫助,甚至覺得某些工作會被AI取代的危機感。而ChatGPT就是基於大型語言模型(large language model, LLM)技術所開發出來的產品,因此,大型語言模型的技術在未來被視為關鍵性的技術,可以為人類生活帶來革命性的影響。
在大型語言模型開發當中,存在不同的種類,大家所熟知的ChatGPT主要是通才模型,主打什麼都會,但是如果要進一步變成專家,其實還是需要有專才的模型,在未來相信如何讓AI模型變成萬事通而且成為每個領域的專家一定是大家在開發上所努力的方向,本篇文章先帶您了解專才模型的開發過程,以了解最新的自然語言模型的發展。
大型語言模型介紹(large language model, LLM)
以前在訓練類神經網路的時候,我們都可以了解到如果類神經網路參數數量太多,反而會有過擬合的現象,也就是模型會死記標準解答而沒有融會貫通,進而造成發揮的效果不如預期。而在自然語言的領域中,卻發現當模型的參數量增加到非常龐大的數量,發揮的效果會更好,因此,在往後的自然語言模型開發上,就會採用大量數據與參數量去建立模型,而這樣建立出來的模型我們就稱為是大型語言模型。舉個例子,像是OpenAI開發GPT3的技術,就擁有1750億的參數量,因此,也需要有非常龐大的文本數據才能訓練完成。由於大型語言模型已經看過非常多的文本數據所學習而成,基本上它可以處理許多通用的自然語言任務。

通用的自然語言任務有許多種,舉例來說,大型語言模型可以處理文本生成的任務,也就是可以產生文章。

雖然可以產生文章,但是文章並沒有達到作家等級的水準。這是因為大型語言模型本來就是大量廣泛學習,學的是一個解決通用自然語言任務的需求。
如果要讓大型語言模型變得更專業,就需要有微調的技巧(fine-tuning),讓模型根據特定的任務需求進行學習,才能讓模型產生的文章可以媲美職業等級的作家。

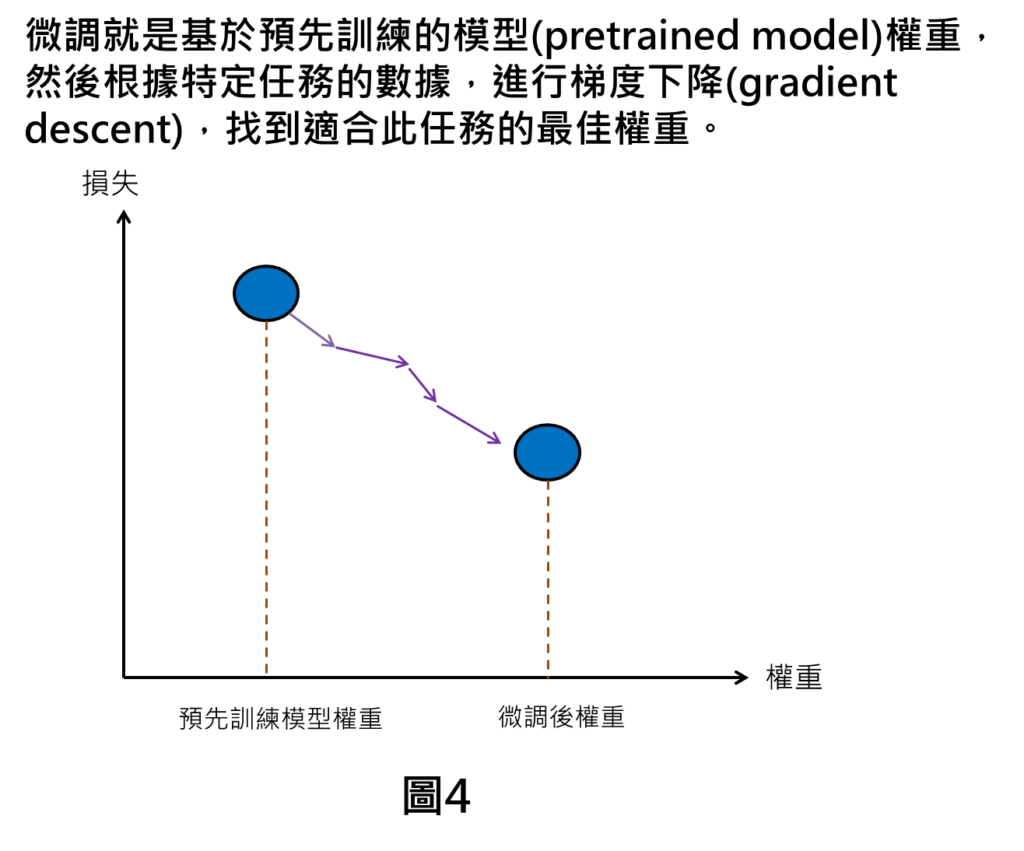
微調(fine-tuning)的原理是什麼?
先前有提到,大型語言模型就是基於非常多數據和參數量所訓練完成的模型,這時候訓練完成的模型就會有相對應的權重,在微調過程中,一開始就是會基於這個預先訓練模型(pretrained model)的權重為基準再去做調整。此時,須給定特定任務的數據,像是如果要讓模型演化成是小說家,就需要準備小說的文本讓模型學習,這時候模型就會根據特定任務提供的數據,在損失函數的空間以梯度下降(gradient descent)之方法,找到最佳的權重,這就是微調的過程。因此,模型的權重就會從預先訓練模型的權重最終移到微調後的權重。
微調的方式為何?怎麼微調?以及微調的範圍為何?
以下我們就把微調的方法整理出來,大致上可分成兩類一個是全微調,另一個是高效參數微調,在高效參數微調裡,又有部分微調,與採用適應器的方式。
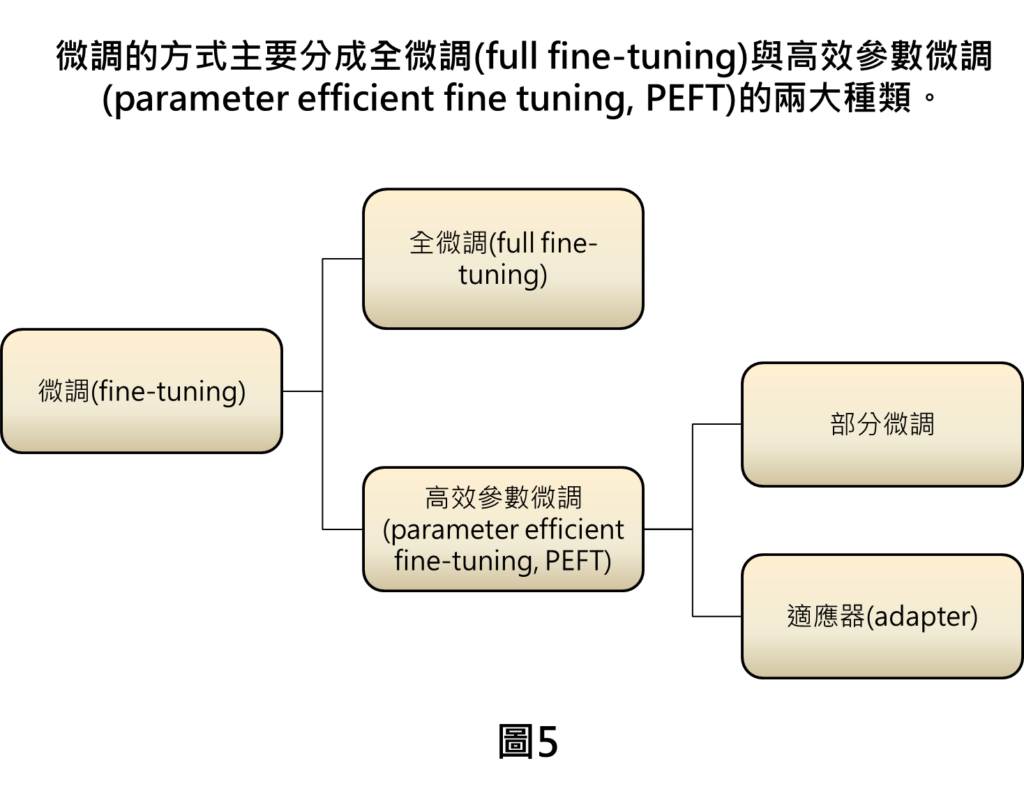
全微調(full fine-tuning)指的是整個大型語言模型的權重都會進行微調,當然在大型語言模型參數量這麼龐大的情況,如果要採用這種方法所耗費的運算資源會太龐大,一般開發者會比較難以進行。因此,就有研究提出高效參數的微調方式(parameter efficient fine tuning, PEFT)。
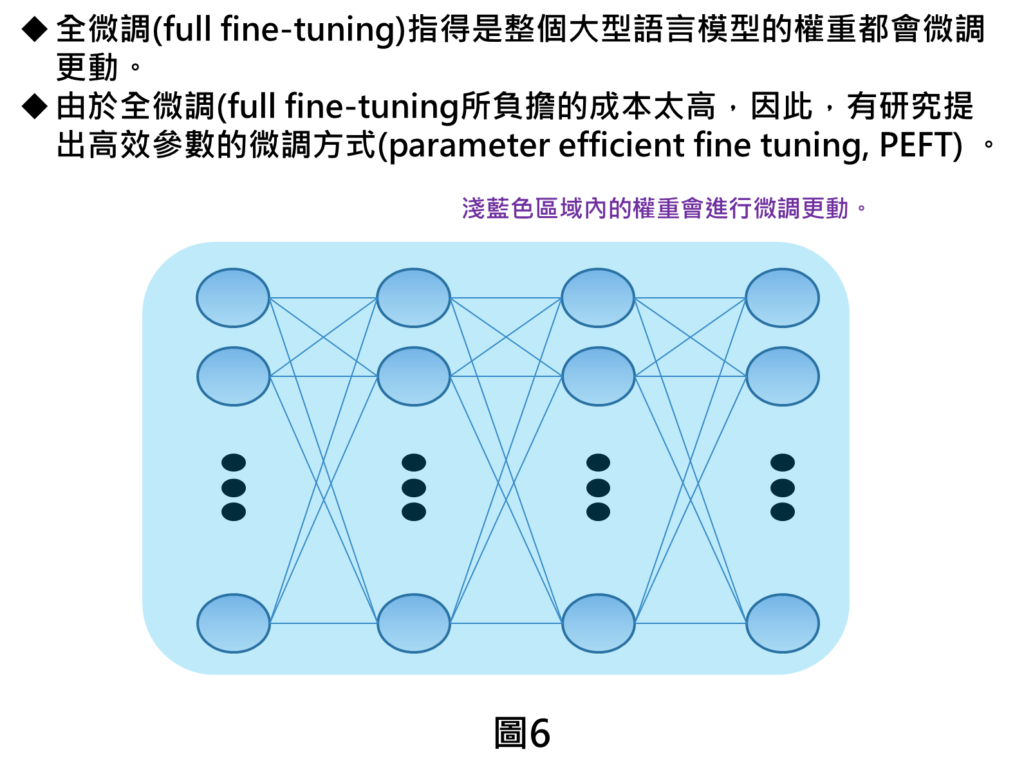
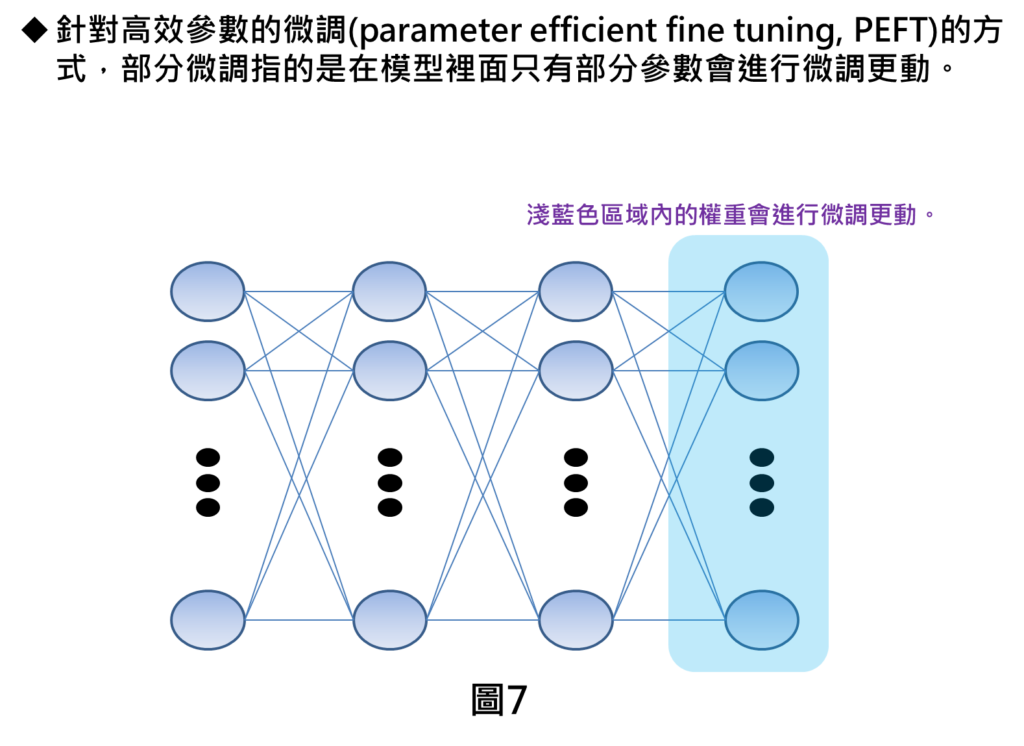
在高效參數微調的方式,部分微調指的是模型裡面只有部分的參數會進行微調,其他區域的參數則保持不變。因為微調更動的參數變少,就可讓一般開發者進行模型的微調。
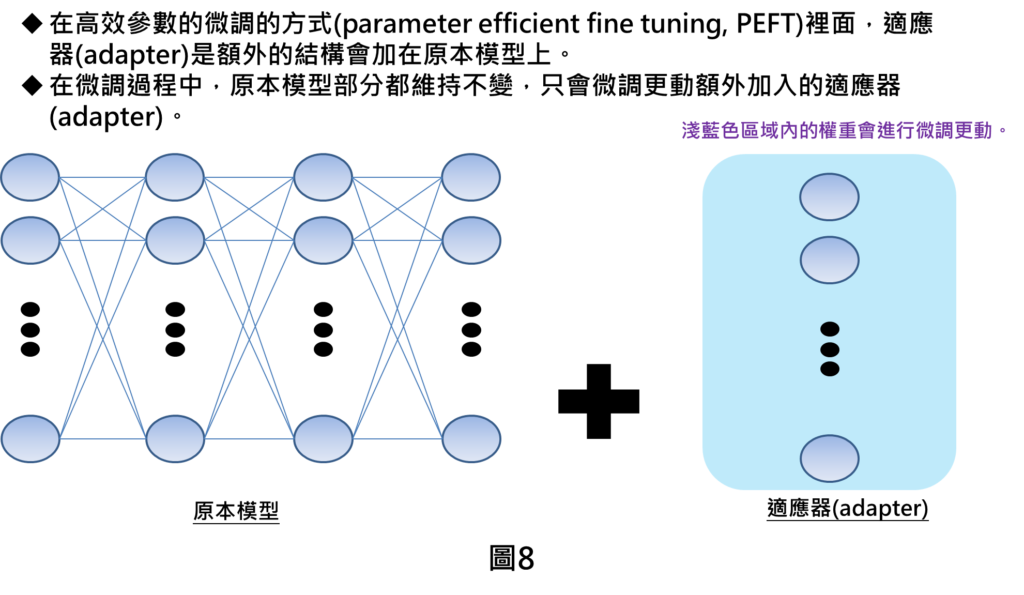
適應器(adapter)則代表會在原本模型插入額外的結構,原本模型的參數都會保持不變,只有在額外加入的適應器部分進行參數的微調更動。在適應器的部分,有許多論文有探討不同加入模型的方式,對模型效果好壞的影響。
結論
本篇文章介紹了大型語言模型以及如何將大型語言模型變成專家的微調技巧。
- 微調的原理: 就是基於預先訓練的模型,還有特定任務的數據,以梯度下降法來作權重的更動,讓模型更可以因應特定任務的需求。
- 微調的方式: 基本上分為全微調與高效參數微調,全微調耗費的成本較多,高效參數微調耗費成本較小,因此是研究上一個熱門的方向,因為對於一般開發者是較可行的選項。
微調方式有很多種,在現今的論文上也有探討許多不同的微調方式,他們目的就是要用較少的運算資源,來達到讓模型可以針對特定任務有著更好的效果。
想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。
[相似文章]:
1.ChatGPT是什麼?探索GPT原理:遷移學習(transfer learning)的奧秘—微調(fine-tuning)技巧
[參考資料]:
2.機器學習與人工神經網路(二):深度學習(Deep Learning)
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]: