

淺談超參數:控制機器學習模型性能的關鍵因子
今天要跟大家分享在機器學習用到的重要概念,也就是超參數。
何謂超參數?
超參數就是模型訓練之前就要決定的參數,以類神經網路為例,模型架構中的層數與節點數就是超參數,這樣的參數並不是像類神經網路裡面的權重可以在模型訓練過程中找到最佳的值,而是要確定好這個超參數後,就要等待機器學習訓練結束之後,才會知道超參數對於模型性能表現的好壞。因此,是需要耗費時間調整的一個過程。

為何超參數會影響模型性能的好壞?
我們這邊以一個簡單的範例來說明,假設目前有兩種模型架構,同樣都有兩個權重,上方的模型,總共有三層,但每一層分別為一個節點,而下方的模型為兩層,在第二層有兩個節點,這兩種情況代表的是有著相同的權重數目,但是超參數卻是不一樣的。
如果我們將這兩種不同超參數的模型進行訓練,則會得到不同的損失空間。
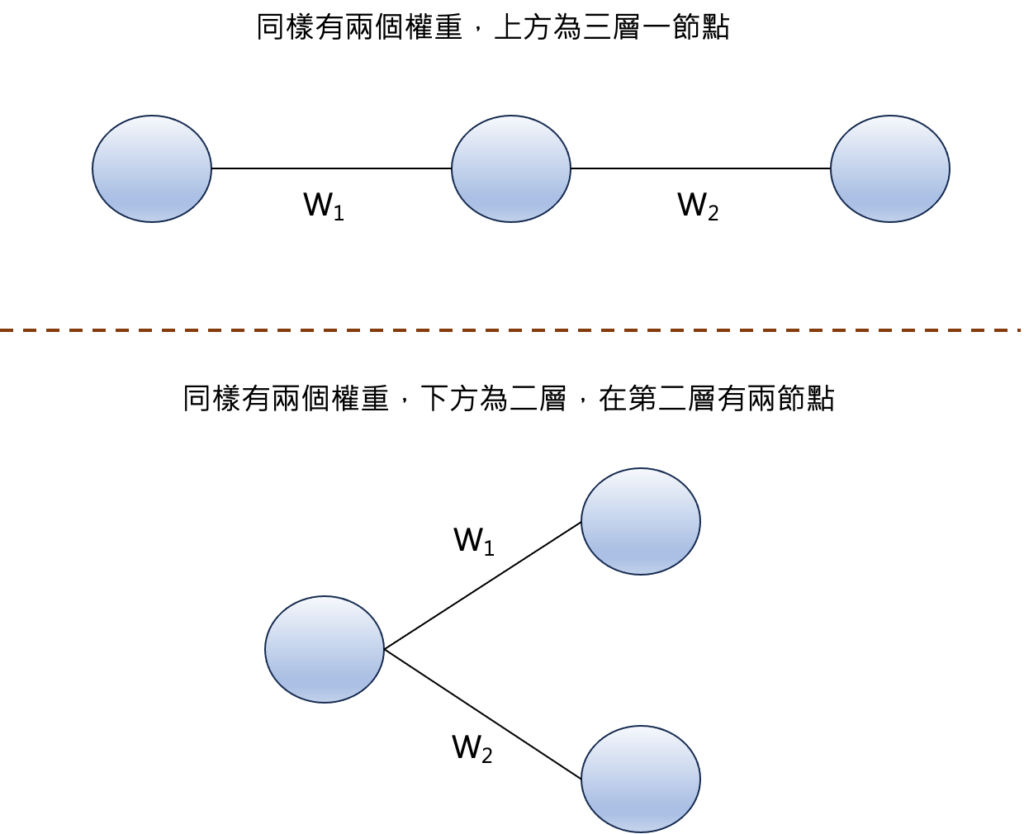
左邊的損失空間是來自於三層一節點的架構,右邊的損失空間是兩層,在第二層有兩節點的架構。我們會發現到兩者的損失空間都不一樣,不一樣的原因是因爲描述模型的數學形式就不相同(三層的一節點的例子是不同層之間的數學關係是函數的函數的關係,而兩層在第二層有兩節點的在不同層的數學關係是僅是單一函數的關係)。
接著我們進一步發現兩者相比,損失的最低點對於左邊的模型來說是落在左下角,對於右邊的模型來說是落在右下角,我們同時將兩者的最低點相比,會發現左邊模型的最低點會比右邊模型的最低點還要低。代表在這兩種超參數對模型性能的表現,是左邊的超參數會較佳。

結論
由我們上面的範例說明可了解到,在同樣權重數目下不同超參數對於模型性能表現就會不一樣了,而且在大部分情況下,不同超參數所對應的權重參數量也大不相同,因此,對於訓練出來的模型效果差異會更大。有鑑於此,我們才需要審慎決定超參數,以得到最佳的模型。
想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。

[參考資料]:
2.機器學習與人工神經網路(二):深度學習(Deep Learning)
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]:




One Comment
Comments are closed.