

分群演算法(cluster analysis)
李彼德的 AI 學習地圖
- 新手必讀: [AI 學習路線圖]|[監督式學習六步驟]
- 核心原理: [什麼是 DNN?] → [Attention 機制] → [Transformer 原理] → [BERT 模型]
- 實作工具: [Gemini 教學]|[Anaconda 安裝]|[Colab 教學]
為什麼要介紹分群演算法(cluster analysis)?
分群演算法是一種非監督式學習(unsupervised learning)的方法,不需要定義每筆資料的標籤就可以實現,耗費處理資料的成本較低,適合應用在不明確的資料上,以初步了解資料的特性跟分布。
分群方法(cluster analysis)是什麼?
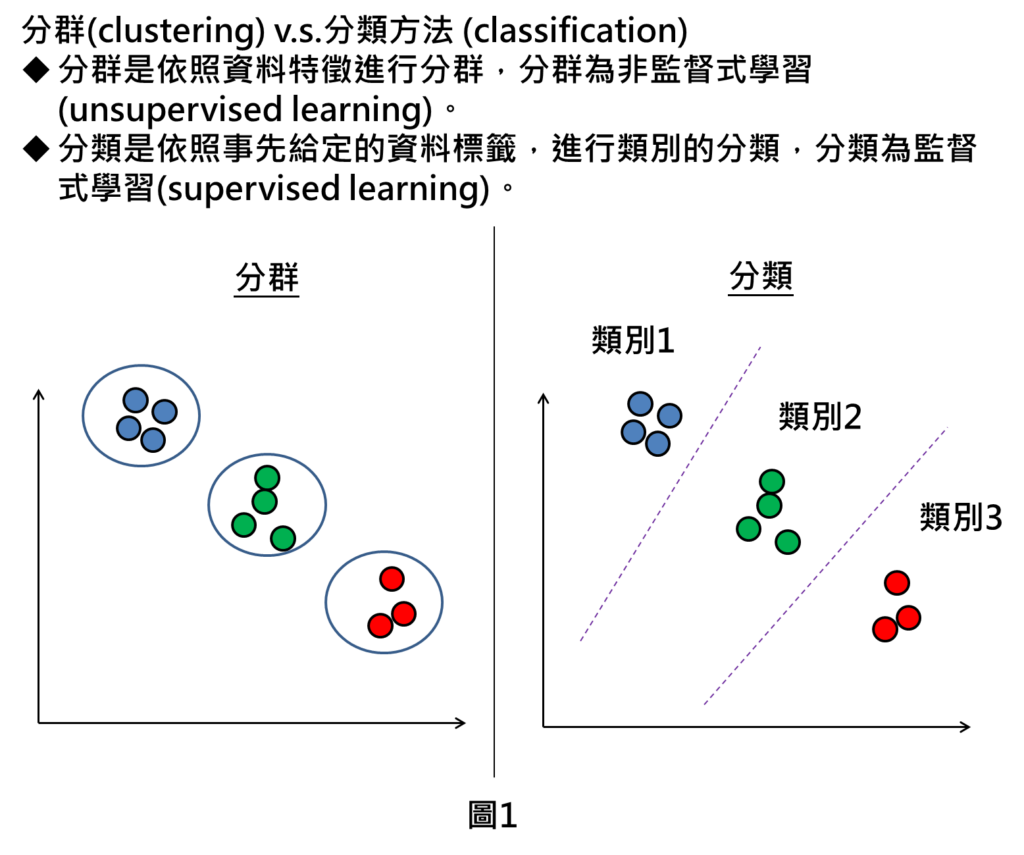
首先,要釐清的點是分群方法(clustering)並不是分類方法(classification) 。
分群方法是依照資料特徵進行分群,資料特徵就像是輸入植物的花瓣長度、寬度等等的訊息,就可將資料進行分群,由於只有給定資料特徵而沒有標籤,這樣的方法並不需要事先給定標準解答,因此,稱為非監督式學習的方法。
分類方法不但要給定資料特徵,也要給定資料標籤,並且要將模型進行訓練,待訓練完成後,才能對類別進行分類,由於須給定資料標籤(標準解答),又稱為是監督式學習。
綜合以上所述,分群方法是將資料點分成一群一群的結果,分類方法是將資料點直接分出屬於哪個類別。
分群原理
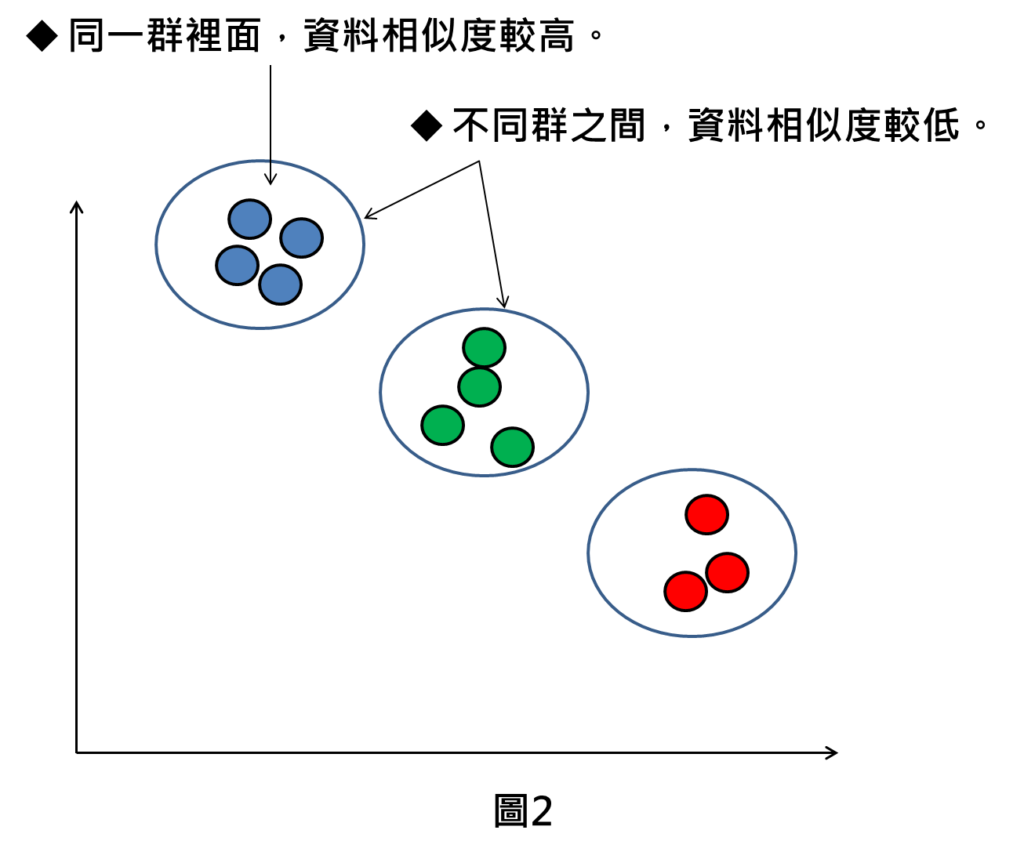
分群的原理如同以上所述,是依照資料的特徵,進行分群。不過在分群方法上還須加入度量的標準,像是加入歐式距離當作度量標準,此時將計算不同資料點之間距離的遠近進行分群,如果資料點之間的距離較近,就視為資料相似度較高,就會分成同一群。
而資料點之間的距離較遠,就會視為資料相似度較低,就會分成不同群。
分群範例
舉例來說,我們想要分出不同植物類別,由於植物類別有太多種類,如果要採用分類方法,處理資料的成本就會很高,因為要從很龐大的資料當中,賦予這些資料確切類別,完成的難度會比較高。此時,就可採用分群方法。

分群方法會直接依照圖片的相似度分群,只要分群結果是正確地的情況下,同一群就會預期是同一種類的植物,不同群是不同種類的植物(因為同一種類的植物特徵是相近的,預期會分成同一群)。雖然乍看之下,無法一下子就分出植物種類,但卻可以分出同一種類與不同種類的植物。後續如果要再進一步區分植物的種類,就可以人為再賦予這些群的標籤即可,這樣就可以大幅減低,像是採用分類的方式,需要給定每一張圖片的類別。

分群方法種類
常見的分群方法有分成是分割、階層、密度分群的方法。分割的方法的特點是簡單,容易理解,易於實現;階層的方法的特點是因為階層法是從頭到尾分完,就可選定想要看特定群的結果,也因為是階層分群,可以看到逐步分群的結果;密度分群的特點是針對不規則形狀的資料點分佈有可以發揮非常好的效果,也不用特定給定分群數目,甚至有找出異常值的效果。

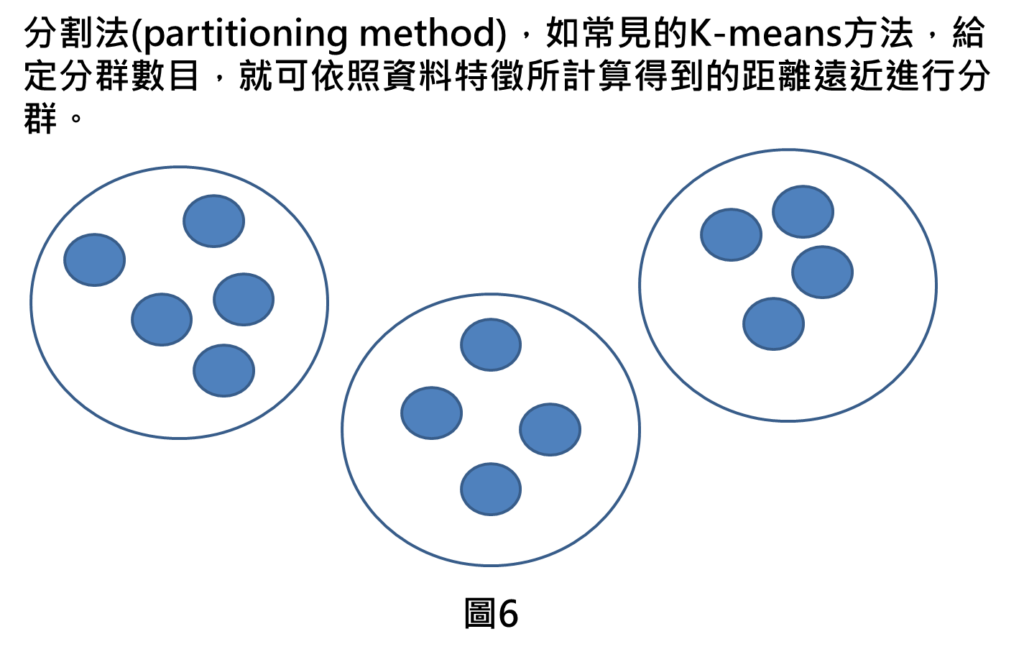
分割法(partitioning method)
如同K-means的方法,需要預先給定分群數目,就可利用資料特徵計算得到距離遠近進行分群。整體是由反覆不斷疊代的方式去做計算,整體的算法簡單、易於實現、易於理解。
階層法(hierarchical method)
階層法(hierarchical method),有分為從上而下,或由下而上的分法。例如從上而下的方法,最上方為同一群會不斷往下分裂,直到最下方為止。可自由選取分群數目看相對應結果。舉例來說,從上而下的方法,一開始整體資料點為同一群,接著每個步驟就不斷分裂,分出兩群,整體從上往下看就會發現分支越變越多,最下面就是將一個資料點分為一群的結果。
整體可以方便觀看分群的結果,例如想要看分兩群的結果,就以藍色虛線的地方畫下去,就可看到分兩群(左半邊為一群,右半邊為一群)的結果。

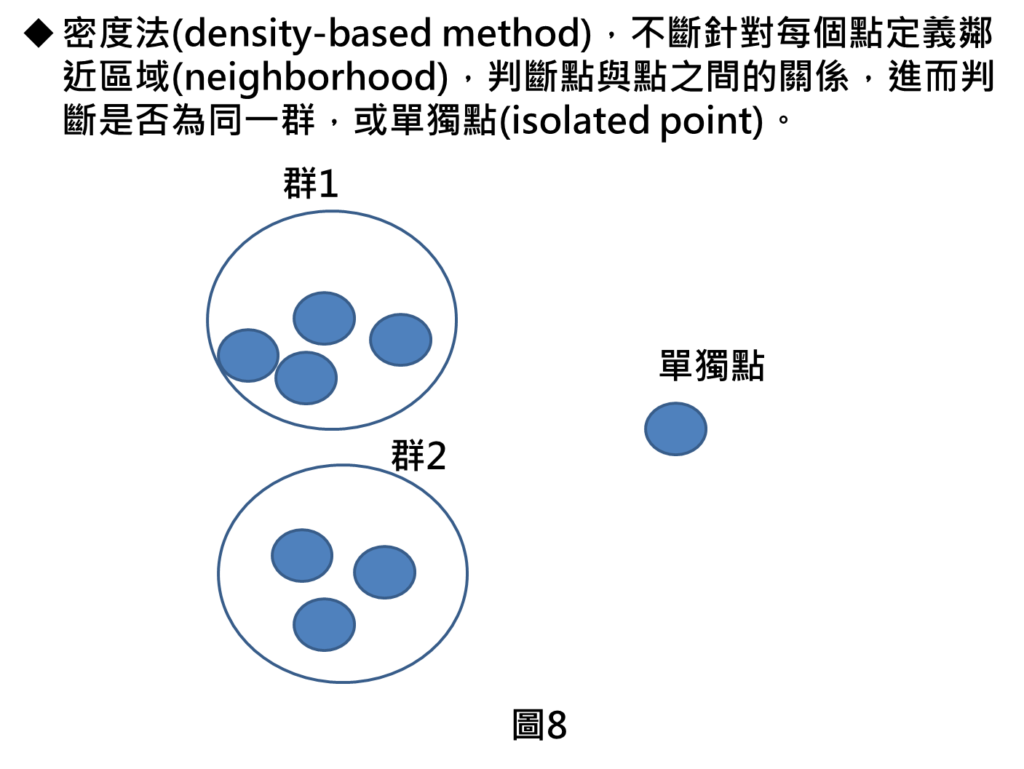
密度法(density-based method)
密度法(density-based method),需要在每一個資料點上去看當下這個資料點與鄰近資料點是否有在鄰近區域內,不斷針對每個點做計算之後,才能判斷資料點到底是不是同一群。如果某些資料點是獨立出來的,鄰近區域內並沒有任何資料點,就會被視為是單獨點,而辨別單獨點的功能就可應用在異常檢測上。
結論
本篇文章介紹
分群方法是什麼
分群方法是依照資料相近進行分群,資料相似為同一群,不相似為不同群。
分群方法的種類
普遍常見有分割,階層,密度分群等等方法,可依照應用需求選定適當方法來解決。
本文大致介紹分群演算法的內容,往後有機會再細部談談每種方法的原理。
想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。
[參考資料]:
2.機器學習與人工神經網路(二):深度學習(Deep Learning)
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]:


