

淺談關於機器學習訓練—不可不知的事情
我們在進行機器學習開發的時候,要從無到有把機器學習模型訓練出來,最重要需要注意的就是數據,因為機器學習本身就是基於數據打造而成的模型,所以數據本身的挑選是十分重要的。好的數據會讓模型變得好。到底我們在機器學習訓練時怎樣的模型才算是好,模型訓練完成的最終目標為何?以及模型開發的數據挑選依據為何?本篇文章帶您了解。
模型的生命週期大概分成兩個階段,一個是開發階段,另一個是佈署階段。
開發階段(model development)代表的是模型在建立的階段,佈署階段則是模型開發完成後,放到實際應用端運行的階段(model deployment)。
在開發階段所牽涉的數據包含訓練數據與測試數據,訓練數據是在模型訓練過程中會用到的數據,機器學習模型就會依據這些數據來進行訓練,以找到最佳權重。而測試數據則是在模型訓練完成後,進行測試用到的數據,而測試數據是要確認模型開發完成的適用性為何?因為有可能模型都是訓練完成,但某些模型是偏向過擬合(over-fitting),是侷限在少部分的情境才能適用,而無法廣泛應用在多種數據類型上。我們開發完模型的目標,一定是想打造一個可以廣法應用的模型,針對不同數據類型,都能準確預測。因此,需要透過測試數據來做調整。
以下我們以一個權重值當作舉例,我們的所期望的機器學習的訓練目標是,當我們決定某個最佳權重值,這個權重在訓練數據與測試數據的所得到的損失都是最低點,這樣才會代表這時候的模型不但可以從訓練數據學習非常好,模型也有一定的廣泛性可適用到測試數據上。
而最終我們期望要將這個訓練完成的模型佈署到實際應用上,因此,我們仍然會期望這樣的權重值在面對到實際的數據,依然會是在損失空間裡面的最小值,代表說模型有著最佳的廣泛性,針對模型開發數據準確而且也適用在實際數據上。
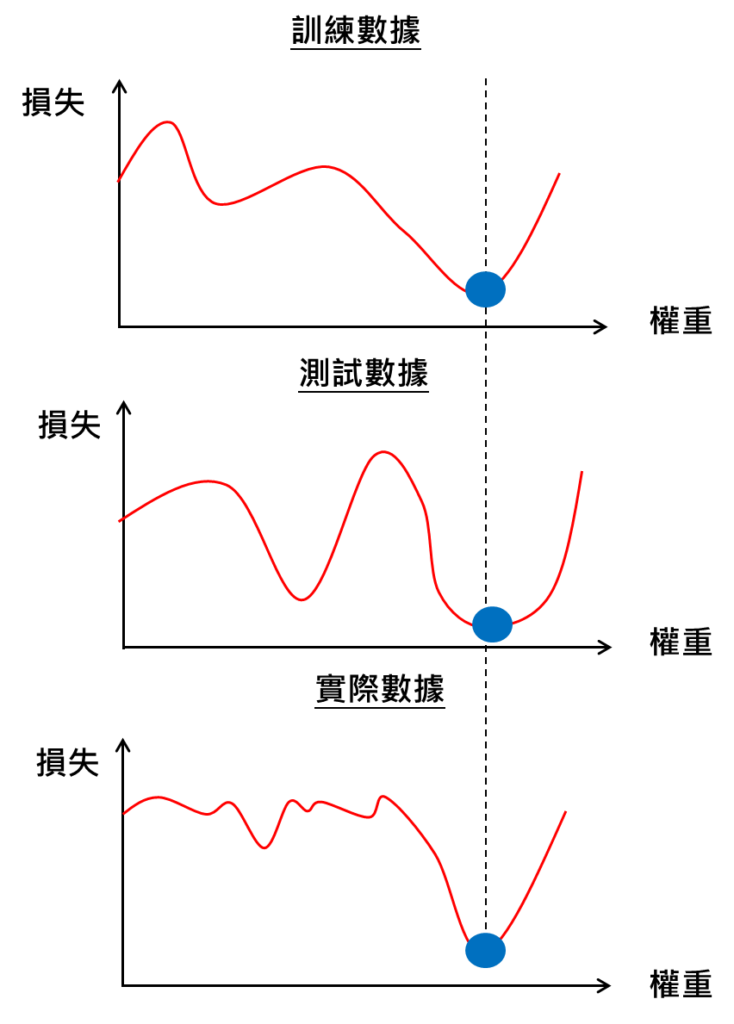
一般在模型開發的階段,尚未有實際接觸到的數據,或是實際的數據非常複雜,有許多可能性。因此,在模型開發數據的部分,主要的目的就是在於可以選定一個最洽當的模型開發數據進行開發,模型在這個開發數據表現良好,我們進而就判定這個模型是ok的,是足以佈署到實際應用上,也期望模型面臨到實際數據的表現是最佳的,這就是模型開發時,如何選定好的開發數據的重要性!
想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。
[參考資料]:
2.機器學習與人工神經網路(二):深度學習(Deep Learning)
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]:



One Comment
Comments are closed.