

深度解析Lasso, Elastic net, Ridge方法
介紹
一般採用的線性回歸方法,有可能因為一味要求誤差降到最小,而造成模型有過擬合現象產生,因而模型有硬記答案的情形。這樣會造成模型在已知解答的發揮效果都非常好,一旦數據偏離已知解答範圍外,模型就會表現不佳。(欲更深入了解可參考淺談Lasso, Elastic net, Ridge方法)
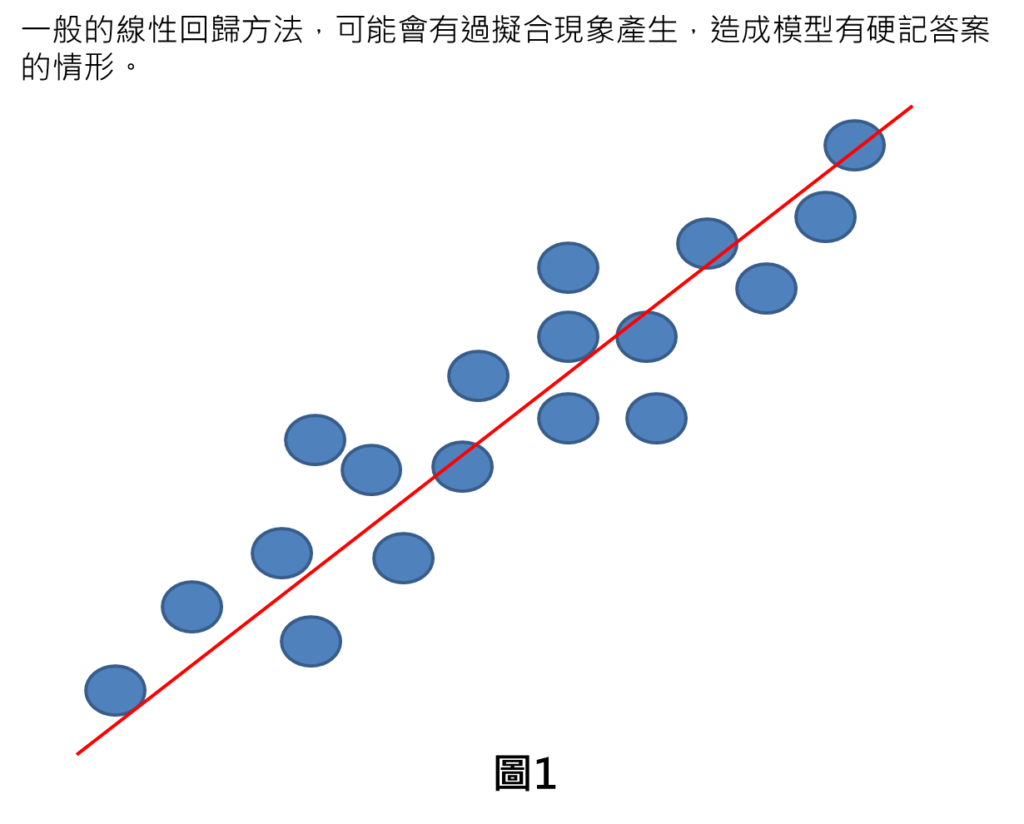
而當線性回歸模型有過擬合現象時,模型裡面的參數,會有過大情形產生。而這樣的現象,剛好可以變成是一個改良回歸模型的方式。

一般線性回歸模型的Loss只有來自於誤差,誤差代表模型與解答的差異。而在改良版的線性回歸方法中,也就是Lasso,Ridge, Elastic Net方法就是在Loss裡面加入懲罰項,以限制參數的大小,目的在於不要讓參數過大,模型就可有良好學習。

Lasso,Ridge,Elastic Net方法差異
懲罰項分別有以下三種,共通的原理就是當參數越大時,則會造成Loss也會增加。因此,模型在訓練過程中,除了誤差要越來越小以外,參數也不能太大。
而Lasso的懲罰項是L1正則化,代表懲罰項大小與參數之間是線性關係。Ridge懲罰項是L2正則化,懲罰項大小與參數是非線性二次方關係,Elastic net懲罰項就是Lasso與Ridge懲罰項的加總。

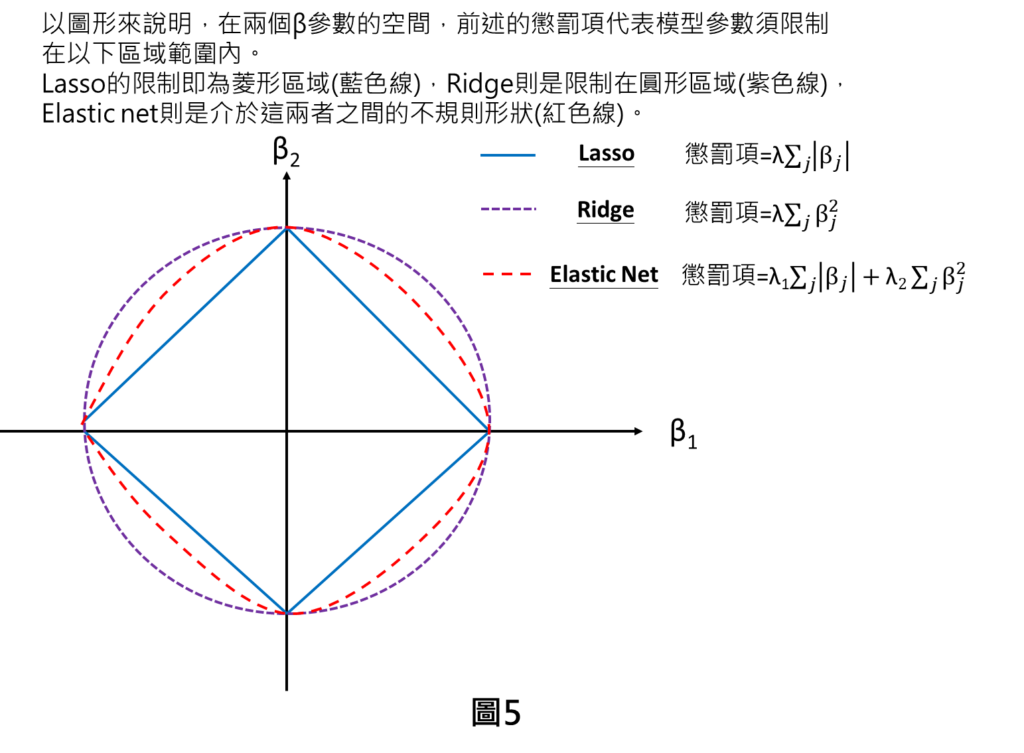
以下是以圖形說明,有兩個參數空間的情況,其實懲罰項的加入代表模型參數須限制在以下區域範圍。Lasso的限制即為菱形區域(藍色線),Ridge則是限制在圓形區域(紫色線),Elastic net則是介於這兩者之間的不規則形狀(紅色線)。我們初步比較就可了解到整體區域限制的範圍大小排序是Ridge範圍最大,其次Elastic net,最小的是Lasso。而這樣幾何的特性,會導致這三套方法有不同的特性產生。
類比法說明—Lasso,Ridge,Elastic Net特性差異
以山谷例子說明,假設在山谷的位置(β1, β2)就是代表模型β參數的大小,高度是loss代表損失的大小,高度越低代表損失越小。一般線性回歸最佳參數的位置是落在山谷,因為這時候Loss最小,也是一般梯度下降法追求的目標。而Lasso,Ridge,Elastic net則須在限制區域內找出最佳參數的位置,因此,最佳參數位置不見得會落在山谷的位置。

以Lasso的方法為例,在圖形上參數位置必須落在菱形的限制區域內,在菱形區域外就不符合Lasso的要求。
觀察山谷的地形,會發現符合在菱形範圍內,同時損失的高度又要比較低的位置,就會落在菱形的頂點(藍色點)。這是因為山谷是在藍色點的右邊,所以越往右邊走,高度下降越多,因此,在菱形頂點(藍色點)的部分,高度是在菱形範圍內高度最低點的地方。
觀察藍色點的位置,β2為零,這就表示為何Lasso的方法會有特徵篩選的功能,因為某些參數可能會變為零,可以過濾掉不必要的特徵。

以Ridge的方法為例,在圖形上參數位置必須落在圓形的限制區域內,觀察山谷的地形,會發現符合在圓形範圍內,高度又比較低,就會落在藍色點位置。
在藍色點的位置,β1與β2都不為零,這就表示Ridge的方法,是會兼顧到不同特徵的考量。

以Elastic net的方法為例,其形狀為不規則的形狀,先前有提到過,其區域會座位在Ridge圓形區域與Lasso菱形區域的範圍之間,因此,可以同時有Lasso跟Ridge的特點,也就是它可能會有特徵篩選的功能,也會有Ridge兼顧不同特徵的功能,Elastic net方法可綜合Lasso與Ridge特點。

總結
Lasso的方法有特徵選擇功能,因此,可適用在輸入比較多的特徵時,而且在這些特徵中並不是每個特徵都是重要的。換句話說,這個適用範圍是用在我們沒有很了解某一個領域,不太了解哪個特徵是不是重要的,那就乾脆輸入很多個特徵,直接讓Lasso的方法決定,哪些特徵要留下,哪些特徵應被拿掉。
Ridge的方法適用在當輸入的特徵都是重要的特徵。這個道理是如果今天很熟悉解決問題的領域,可以很清楚了解到哪個特徵是重要的,然後我們只輸入重要的特徵,那就不需要特徵篩選,就可直接採用Ridge方法進行預測。
Elastic Net則是綜合上述兩者方法的特點,可適用在覺得不是每個特徵都是非常重要的特徵以及也不想要像Lasso有那麼強的特徵篩選功能,就可使用。換句話說,當今天輸入的特徵,沒有很有把握覺得每個特徵都是重要的,覺得大部分特徵也是重要的,然後要想把部分特徵篩選掉,如果用Lasso的話,可能會篩選掉重要的特徵,會沒有把握,就會採用Elastic net這種比較溫和的作法,想保留重要特徵,同時又可以把部分特徵篩選掉。
至於在篩選特徵跟保留特徵之間,到底比例要怎麼調整,其實Elasitc Net裡面也有超參數進行調整,以讓使用者覺得Elastic Net的特性要多偏向Lasso還是多偏向Ridge,這是可以再去作調整的,因此,我認為Elastic net在使用上的彈性也會相當大。

想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。
[相似文章]:
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]:
![[好書推薦] 從零開始理解深度學習,易讀的圖解AI書籍](https://peterlihouse.com/wp-content/uploads/2025/04/image-150x150.png)


