Transformer核心原理: 從三個Multi-Head Attention角度,白話文範例帶您了解
李彼德的 AI 學習地圖
- 新手必讀: [AI 學習路線圖]|[監督式學習六步驟]
- 核心原理: [什麼是 DNN?] → [Attention 機制] → [Transformer 原理] → [BERT 模型]
- 實作工具: [Gemini 教學]|[Anaconda 安裝]|[Colab 教學]
Why Transformer?
傳統RNN的架構是採用時序性的類神經網路進行自然語言的處理,這樣的方式就是透過時序方式一步一步解讀輸入的文字,彙整後再將編碼訊息傳遞到解碼器中,再得到最終輸出。
如果在輸入的文字長度很長的時候,由於需要一步一步解讀文字,部分的訊息會丟失掉,造成自然語言任務處理效果較差。
另外,因為時序性的類神經網路計算,需要一個接著一個計算,導致運算上並沒有辦法進行平行運算,導致整體運算效率較差。
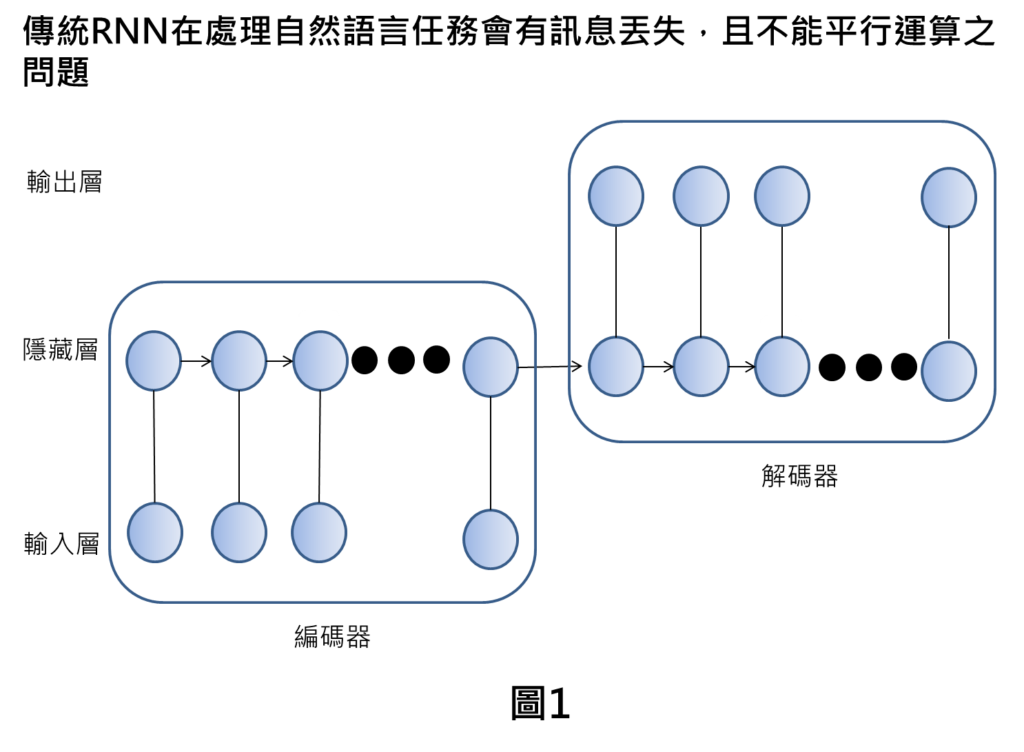
Google發表的創新文章,提出Transformer架構,就是可以解決上述傳統RNN的限制,其做法上在於不需要依賴原有RNN的架構,利用一個開創性的架構,就可突破傳統RNN限制,使得自然語言處理變的更有效,在計算上更有效率。
Transformer介紹
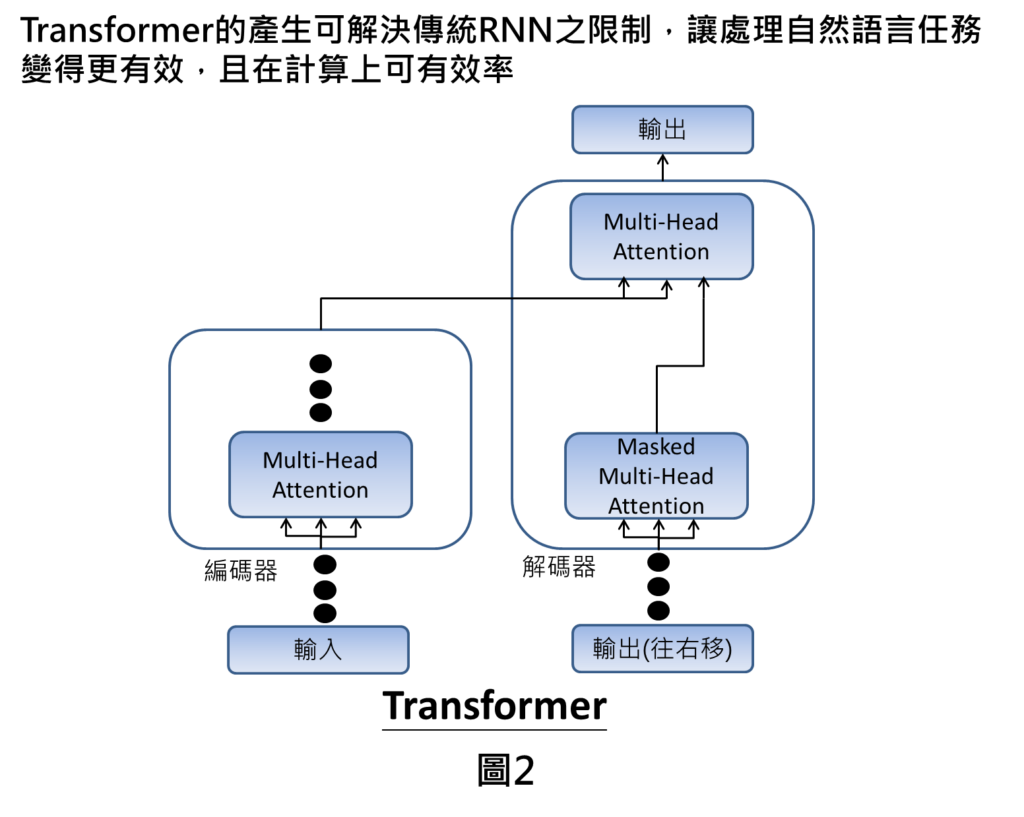
Transformer的架構相當複雜,一開始接觸到這個概念,為了避免混淆大家的理解,我們先講解Transformer比較核心的概念,讓大家簡單理解Transformer在做什麼事情。由於Transformer核心的概念就是來自於Attention機制,因此,我們就以此為出發點跟大家來做介紹。
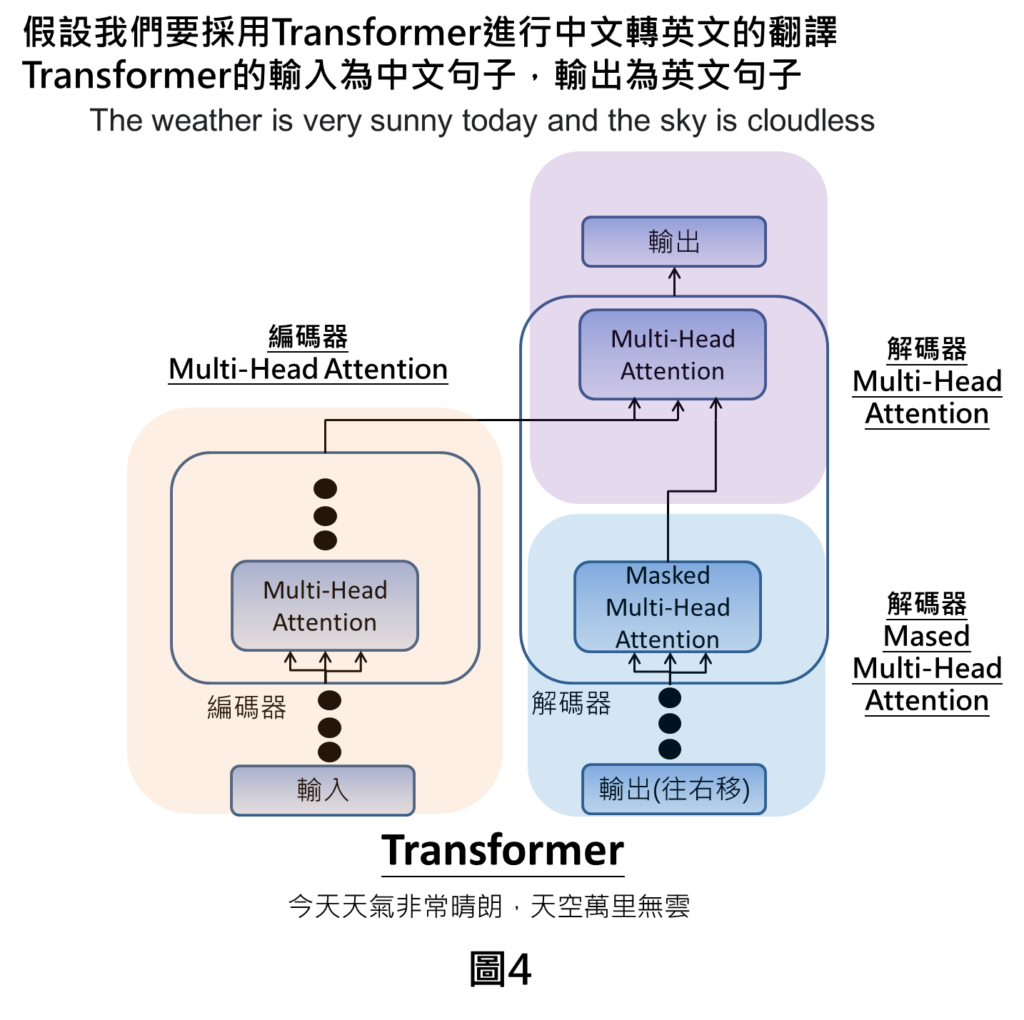
整體Transformer的架構是在輸入的部分即為文字,輸入文字進來之後會進到編碼器當中,編碼器裡面有Multi-Head Attention的機制,經由attention計算之後,會將編碼訊息傳送到解碼器當中。另一方面,在解碼器部分也會在輸入端接收來自於先前產生的輸出訊息(我們在圖中稱為輸出往右移),就會進到Masked Multi-Head Attention的機制,處理完之後,就會在最上方的Multi Head Attention的部分彙整來自於編碼器的訊息以及來自於Masked Multi Head Attention的訊息,彙整完以後,我們即可得到輸出。上述提到的三個Attention機制就是Transformer裡面核心的概念,這三個Attention的機制可以1.讓自然語言處理任務上變得更有效,可以更關注在重要的訊息上面,也可以改善整體運算的效率。
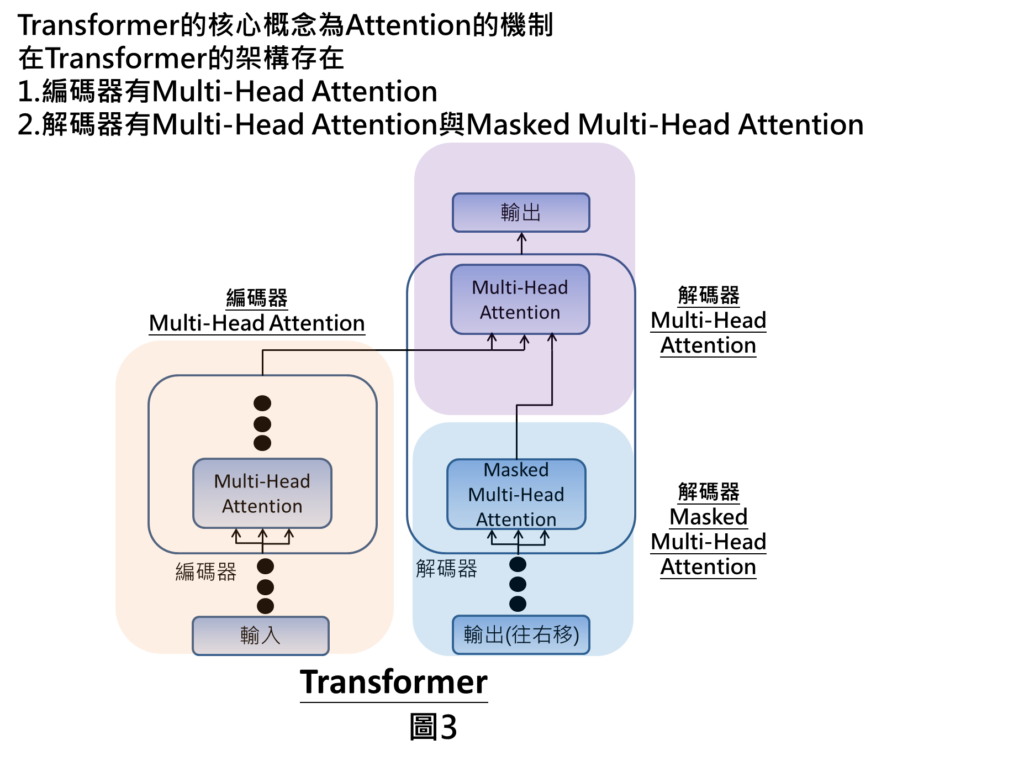
舉例來說,假設我們要實現中翻英的功能,輸入端為中文句子像是今天天氣非常晴朗,天空萬里無雲,經由Transformer的運算後,可得到最終輸出為The weather is very sunny today and the sky is cloudless。
編碼器Multi Head Attention
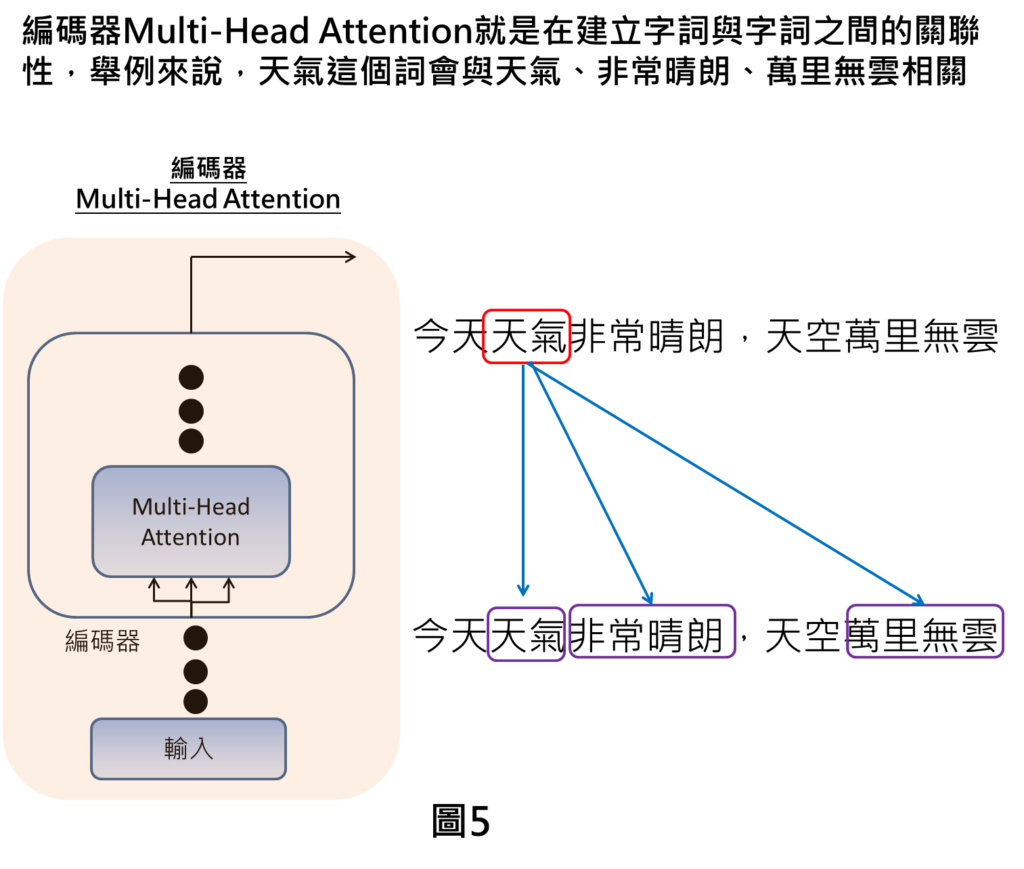
當我們輸入中文句子之後,在編碼器裡Multi-Head Attention的作用就是會去計算字詞與字詞之間的關聯性,才能讓我們了解哪些字詞是重要的,讓我們關注在那些重要的字詞上面。
舉例來說,當我們關注在天氣的字詞,就會將天氣的字詞與其他字詞互相對應,計算字詞之間的關聯性,像是天氣這個字詞,會跟天氣、非常晴朗、萬里無雲比較關聯,代表講到天氣的字詞,我們就會較關注在這些字詞上。
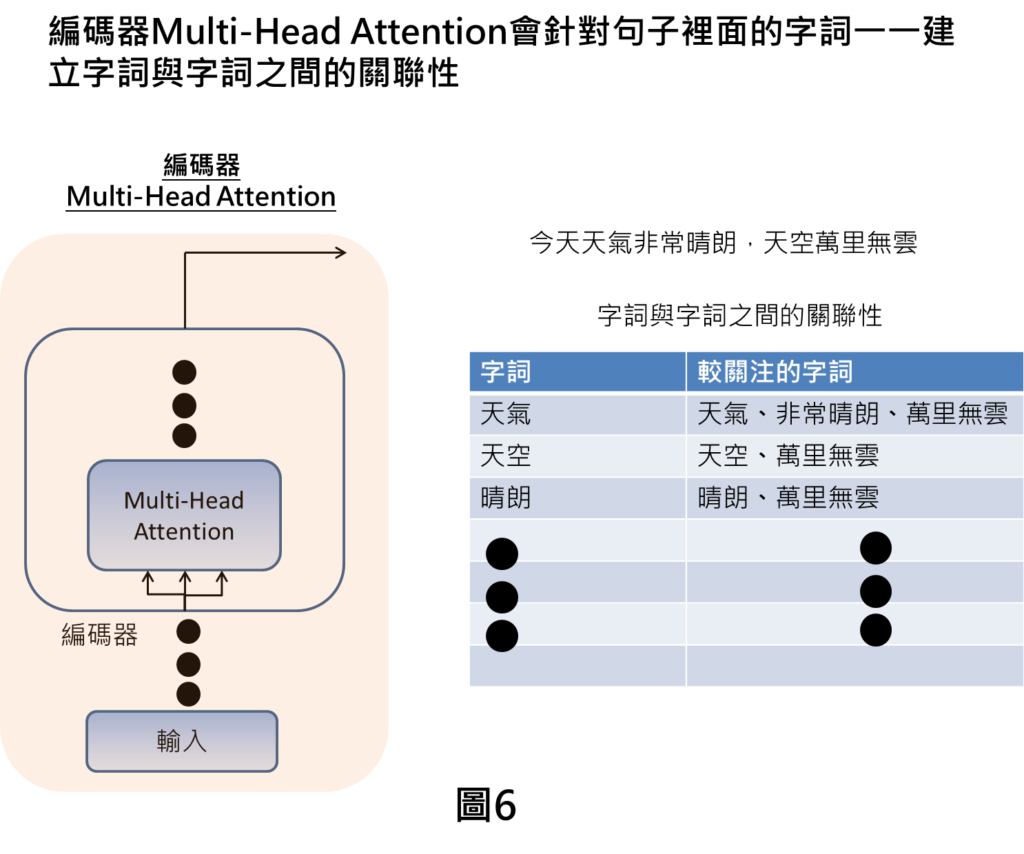
接下來,會將句子裡面的字詞一一與不同的字詞互相對應,就會有字詞與字詞之間關聯性的訊息,像是講到天氣,會較關注在天氣、非常晴朗、萬里無雲,講到天空,會較關注在天空、萬里無雲的字詞上。
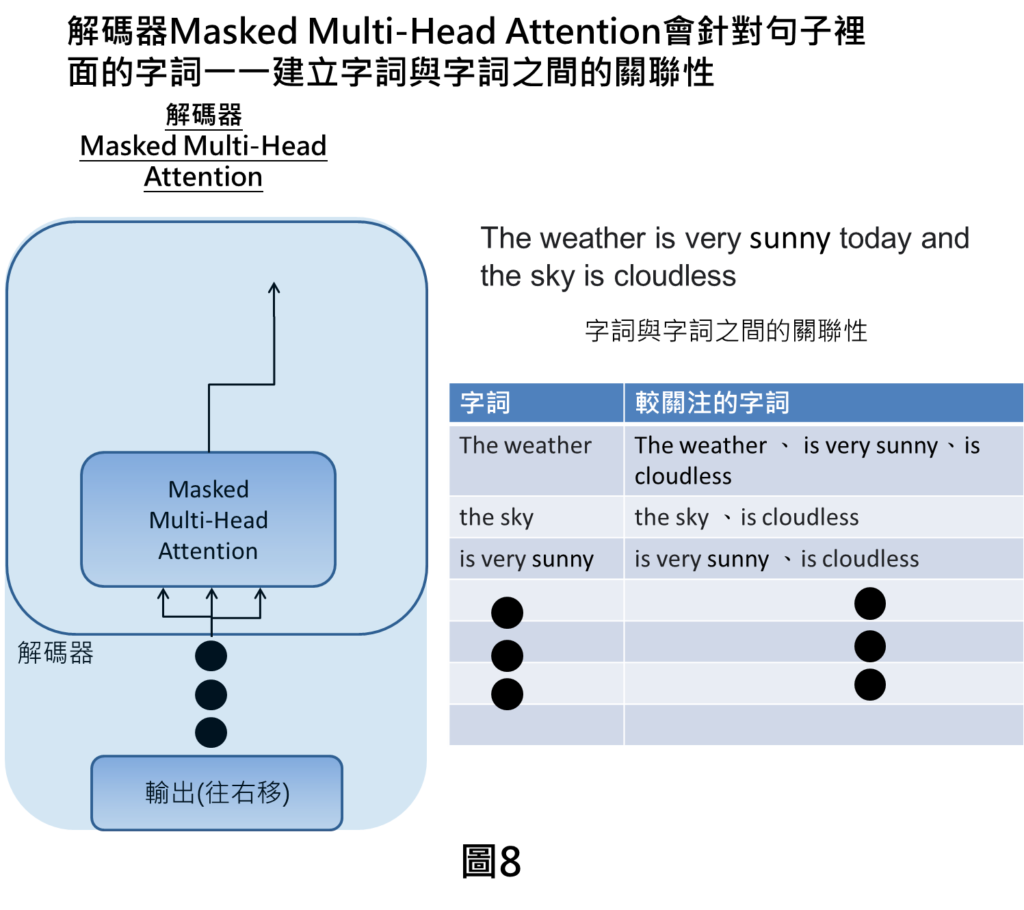
解碼器Masked Multi Head Attention
在解碼器的部分也是一樣在尋找字詞與字詞之間的關聯性,在解碼器的輸入為輸出(往右移)這個意思是解碼器會接收來自於上個預測的輸出,舉例來說,第一個時刻就沒有解碼器輸入,第一個時刻會有解碼器輸出,之後第一時刻的解碼器輸出就會當作後一時刻解碼器的輸入,然後在預測後一個時刻的解碼器輸出。
在中翻英的例子,解碼器的輸入就是前個時刻的輸出也就是英文句子,這時候我們就會看這個句子裡面字詞與字詞之間的關聯性。
像是The weather這個詞會與The weather 、 is very sunny 、is cloudless,互相關聯。
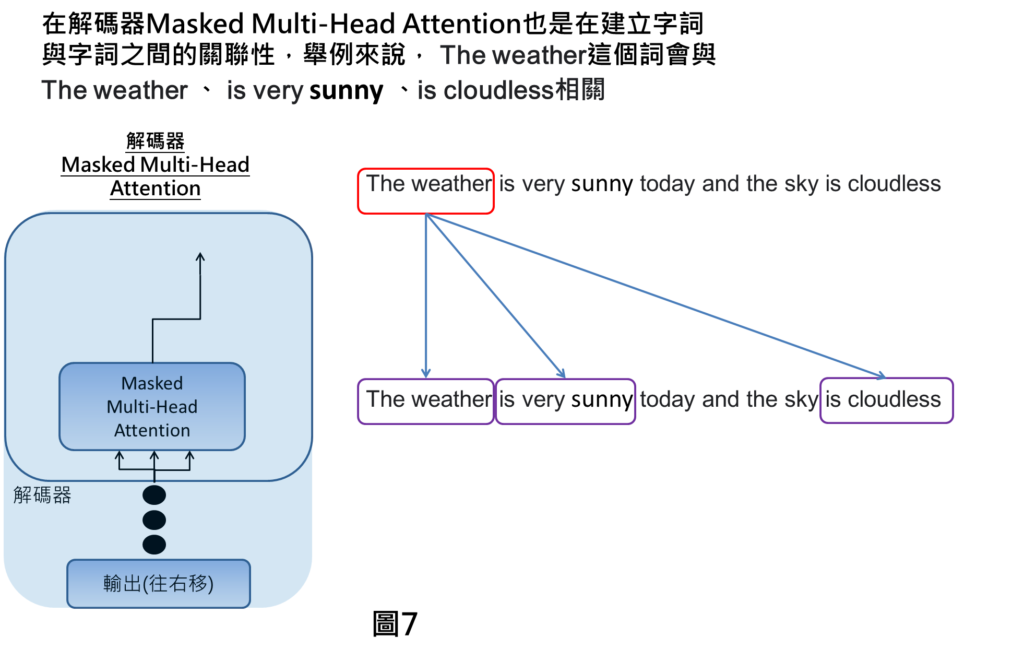
之後,會一一對每個字詞尋找關聯性,就可建立字詞與字詞之間關聯性的關係。講到the weather的部分就會關注在The weather 、 is very sunny 、is cloudless,依此類推。
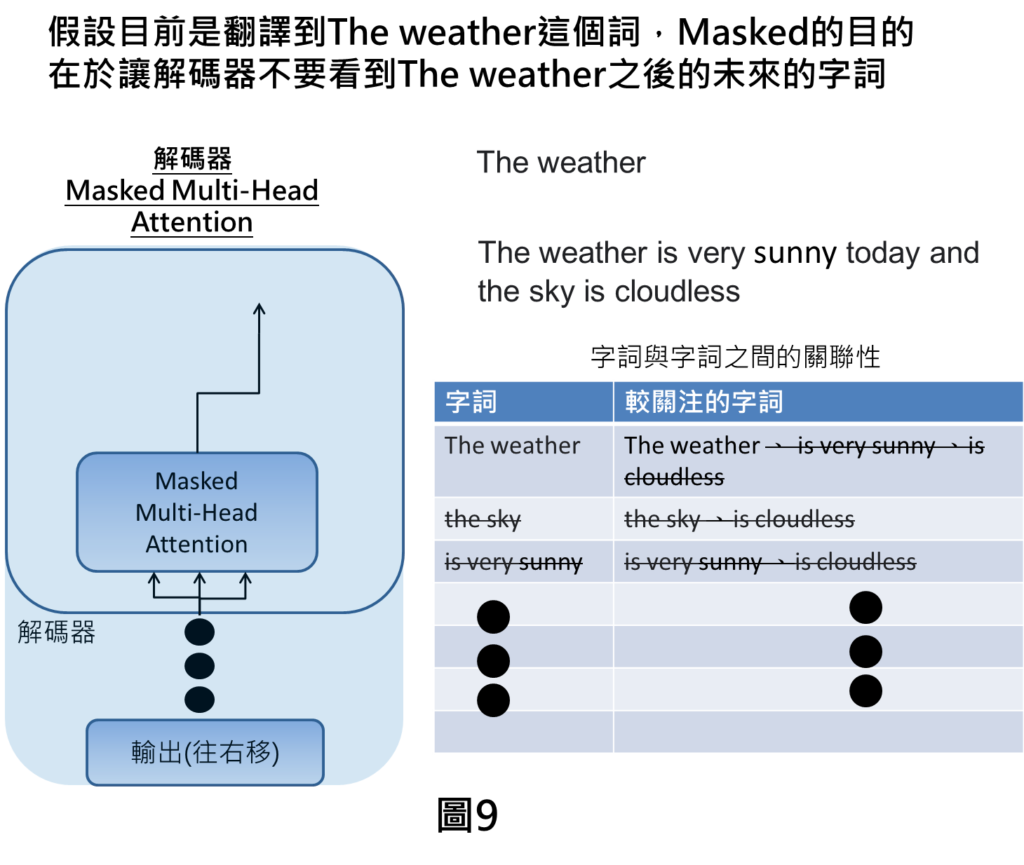
Masked的意思是在訓練的時候,我們會準備好許多中文與英文翻譯的例子,在輸入這些例子去訓練的時候,我們在解碼器輸入的部分,並不會真正輸入前一時刻的輸出,而是會直接輸入標準解答,也就是會將英文句子往右移,來表示解碼器可輸入先前的解碼器輸出。
這是因為在訓練的時候,假設在解碼器輸入是真正擷取上一個時刻的輸出,那麼有可能上一個時刻輸出預測錯的話,就會導致在訓練效果較差,因此,在訓練過程中,我們會採用標準解答來讓機器好好學習。
但是這樣會產生問題,也就是當我們翻譯到The weather的這個字詞時,就需要將The weather後面的字詞忽略掉,因為那些是未來的字詞,我們根本不應該考慮The weather與未來字詞的關聯性。
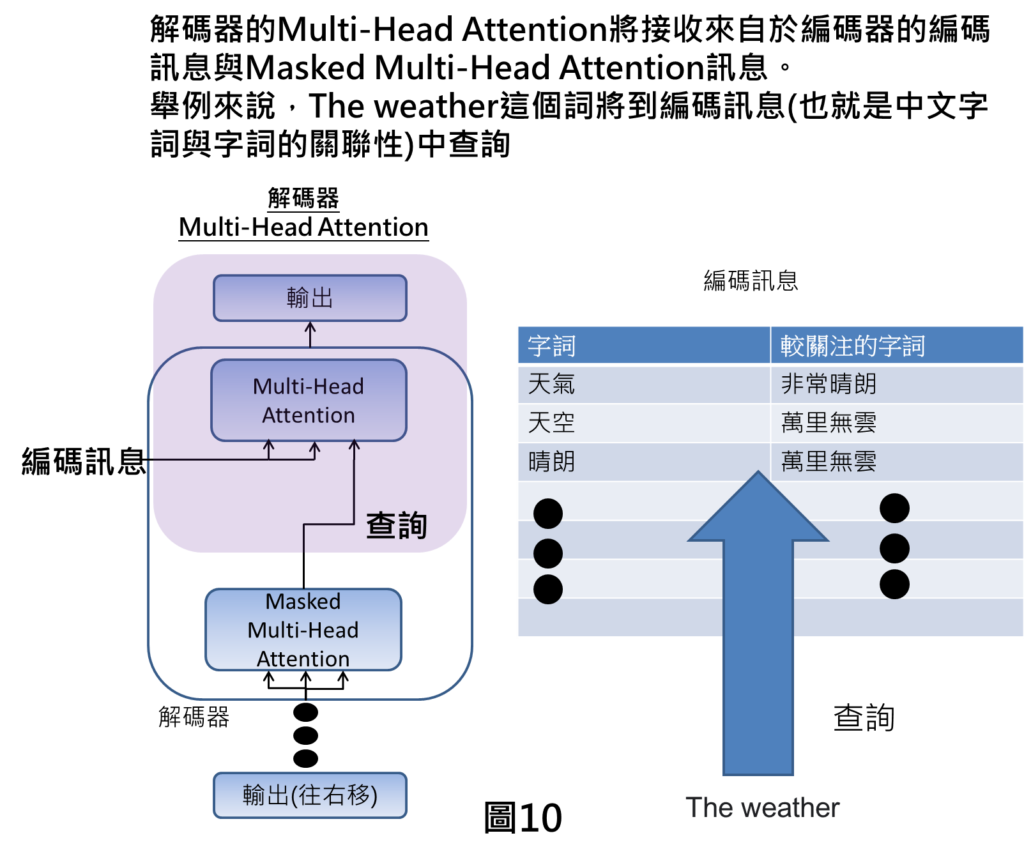
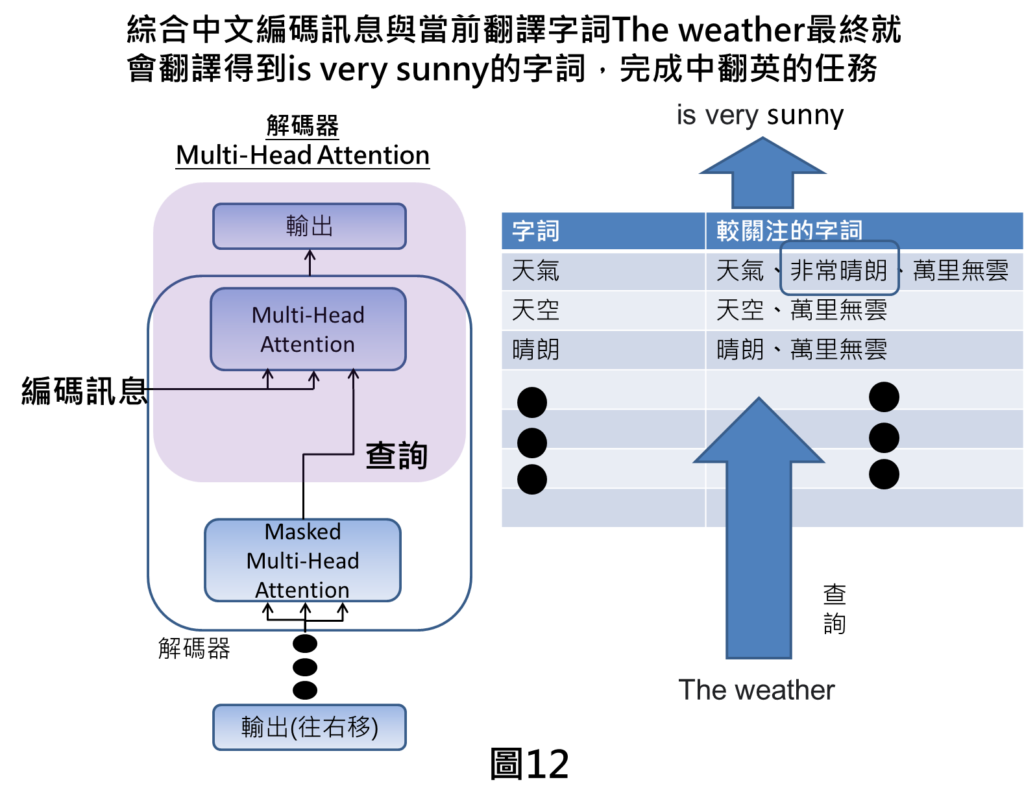
解碼器Multi Head Attention
最終在上方的Multi Head Attention,是接收來自於編碼器的編碼訊息,以及來自於Masked Multi Head Attention的訊息,舉例來說,像是我們翻譯到The weather,就會將這個字詞丟到編碼訊息當中進行查詢。
查詢之後會發現The weather會與天氣很相關,然後我們又可以了解到天氣會與天氣、非常晴朗、萬里無雲相關。天氣是本身自己的字詞就不要看,那非常晴朗的權重可能比較高的情況下,此時,機器就會比較關注在非常晴朗的字詞上面。
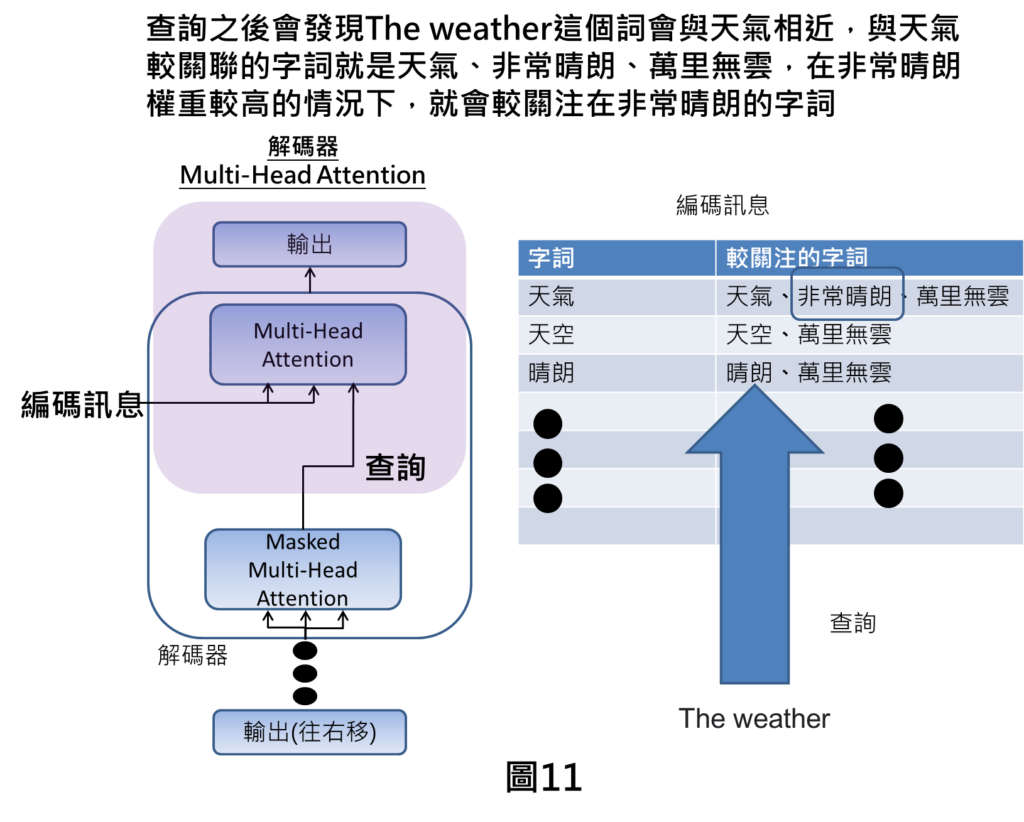
由於天氣與非常晴朗相關,綜合中文編碼訊息與當前翻譯英文字詞的結果,就會得到輸出為is very sunny,就可以完成中翻英的任務。
結論
透過Transformer的Attention的機制,因為可以有字詞與字詞關聯性,所以我們可以很清楚了解到在講到某個字詞的時候,需要關注哪些重要的字詞,這樣就能確保訊息是有效而且不丟失,使得在自然語言處理上效果會好。
另外,由於是直接採用關聯性的計算方式,並不用依照時序性的類神經網路來進行計算,因此,我們就可平行化計算,大幅縮短運算時間。

想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。
[參考資料]:
[相似文章]:
1.Transformer介紹:為何它是現今NLP技術發展的基石?
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]: