

半監督式學習Semi-Supervised Learning
為何需要半監督式學習Semi-Supervised Learning?
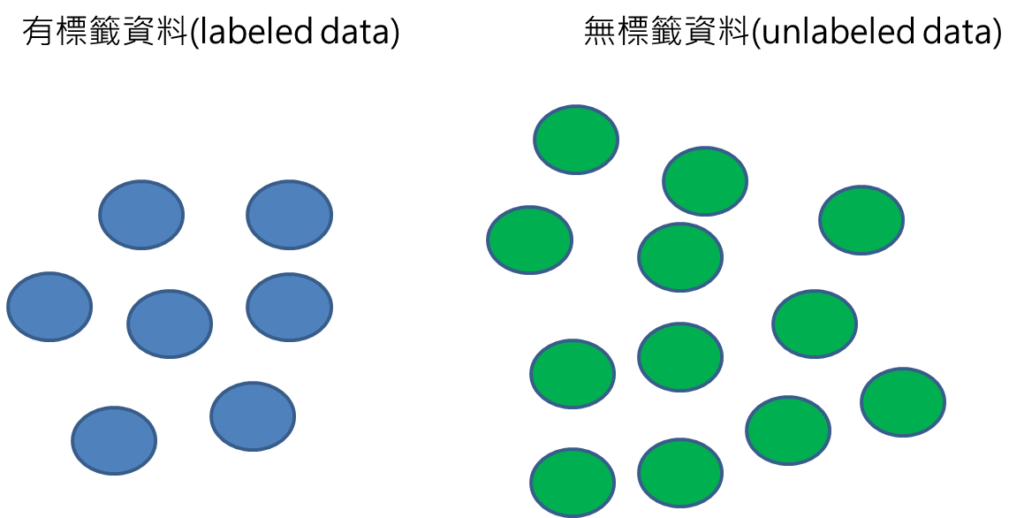
在某些應用場景,由於標註資料不易取得,往往資料集裡面就會有標籤的資料labeled以及無標籤的資料unlabeled data 混雜在一起,甚至無標籤資料量會比有標籤資料量更多,這時候如果採用監督式學習,由於資料量太少的關係,建立的模型效能就會不佳,這時候就需要有半監督式學習來處理這樣的資料,以提升模型的效能。
那到底半監督式學習Semi-Supervised Learning是如何運作的呢?
最主要的核心概念是,需要採用不同方法將無標籤資料納入訓練過程,雖然這些無標籤資料沒有標籤,無法立即使用監督式學習,但是這些資料仍然存在特徵,可以善用這些有的特徵,用不同方法做若干處理,可有效提升模型預測的精確度。
半監督式學習Semi-Supervised Learning有許多種處理方法,其中一種比較簡單的是self-training。以下我們以不同步驟來說明。
步驟
步驟1: 取得資料集,分成有標籤與無標籤的資料。
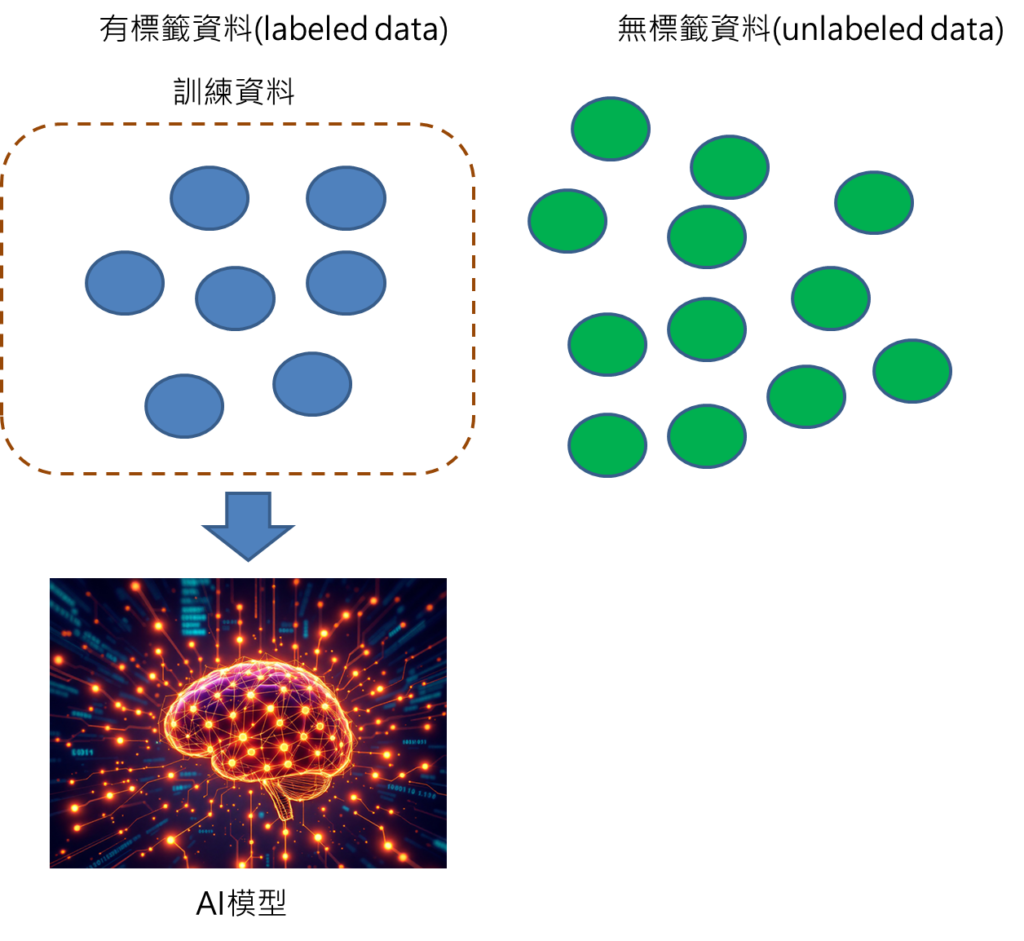
步驟2: 利用有標籤資料建立預測模型。
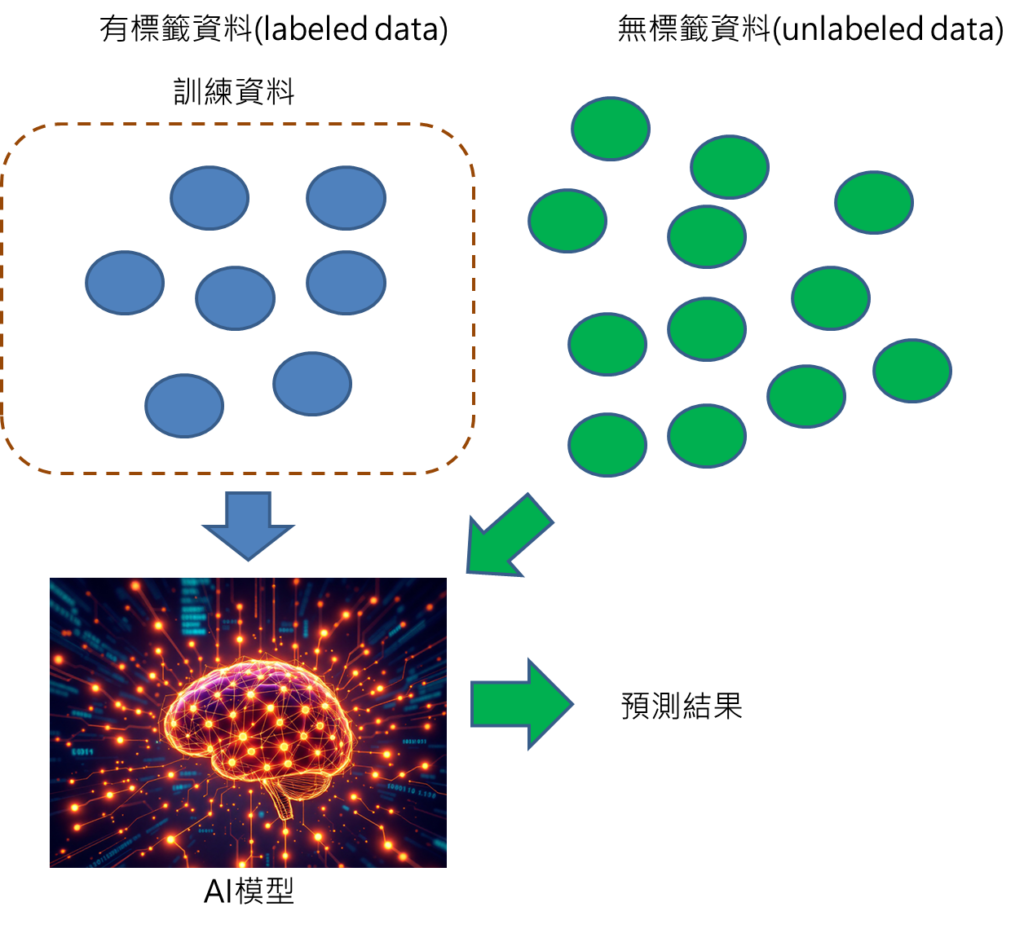
步驟3: 輸入無標籤資料至AI模型中進行預測,取得預測結果。
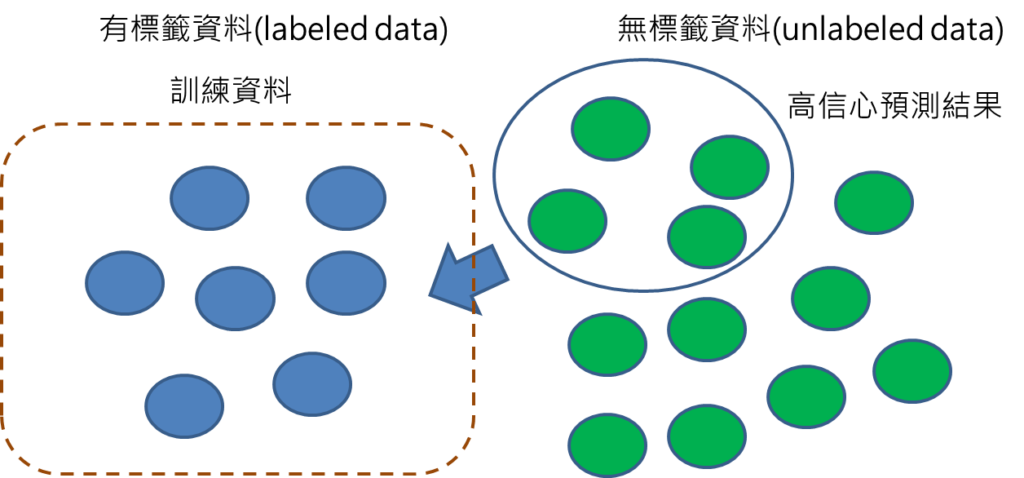
步驟4: 選擇預測高信心度的資料,將這些資料的預測結果視為標籤。
從步驟3可取得許多預測結果,但是模型對這些預測結果,未必每個都非常有把握,所以要從中挑選較為可靠的預測結果,也就是選擇高信心度的資料,將這些資料的預測結果變為標籤,標註在這些資料上面。
步驟5: 將有標籤資料再加入訓練資料集,重新對模型進行訓練。
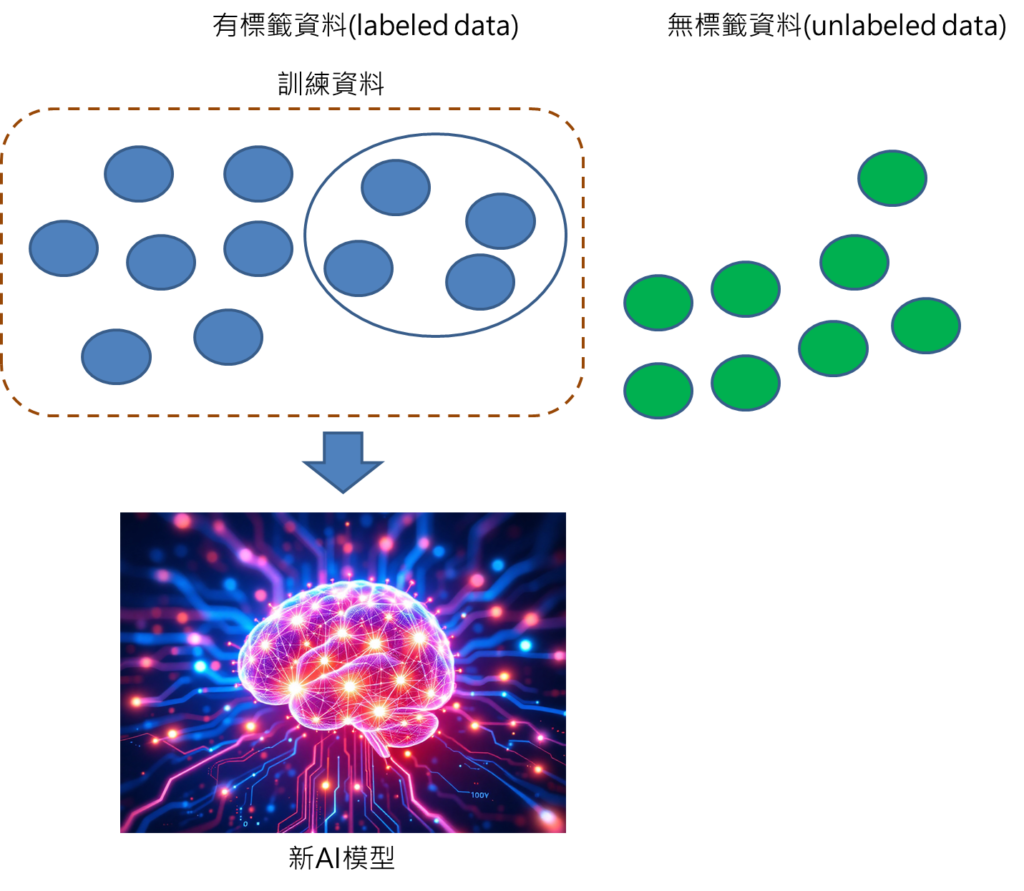
步驟6: 重複以上步驟2到5。
接下來就是重複步驟,繼續利用產生的新模型,再重新對無標籤的資料進行預測,選擇高信心度資料視為標籤,再加入訓練資料,重新訓練模型,反覆這樣過程。
結論
透過這些過程,就可以將原本無標籤的資料,變成有標籤的資料,然後擴大訓練資料集,提升模型的精確度。這是比較簡單的半監督式學習方法,再使用self training的方法時候,也必須要注意到這個做法會很仰賴初始的訓練資料集所建立的模型,因此,如何確保此模型再預測無標籤資料的結果,有一定的精確度,是非常重要的考量部分。
想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。
其它文章:
最近AI原理文章:
Stable Diffusion原理: 文字生成圖片簡易說明
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]:


