

BERT模型介紹: 大型語言模型基石
介紹
今天跟想跟大家分享BERT模型,雖然在現在有很多的大語言模型LLM,但是BERT仍然是一個很經典的模型。它是基於Transformer框架所建立的大語言模型,也有開源出來,大家有針對這個模型做了很多後續的應用,所以也可以有很多資源可參考,再依照自己需求去開發功能,像是情感分析,語意理解等等的應用,因此,了解BERT模型是非常重要的一個基礎。
與目前最火紅的GPT相比,BERT的類型完全與GPT不相同,GPT是decoder為基礎的模型,而BERT是encoder為基礎,GPT是著重在文本生成,BERT是著重在語意理解。各自有相對應的優點與缺點。
BERT原理是什麼呢?
BERT是基於Transformer的架構,Transformer是基於attention機制的開發的技術。
在先前我們有提到Transformer的原理機制,也就是Transformer的架構是由多個編碼器與解碼器所組成,在編碼器與解碼器裡面主要有Multi-head attention的運作機制,一般的Transormer結構是有N=6個編碼器(encoder)與解碼器(decoder)。
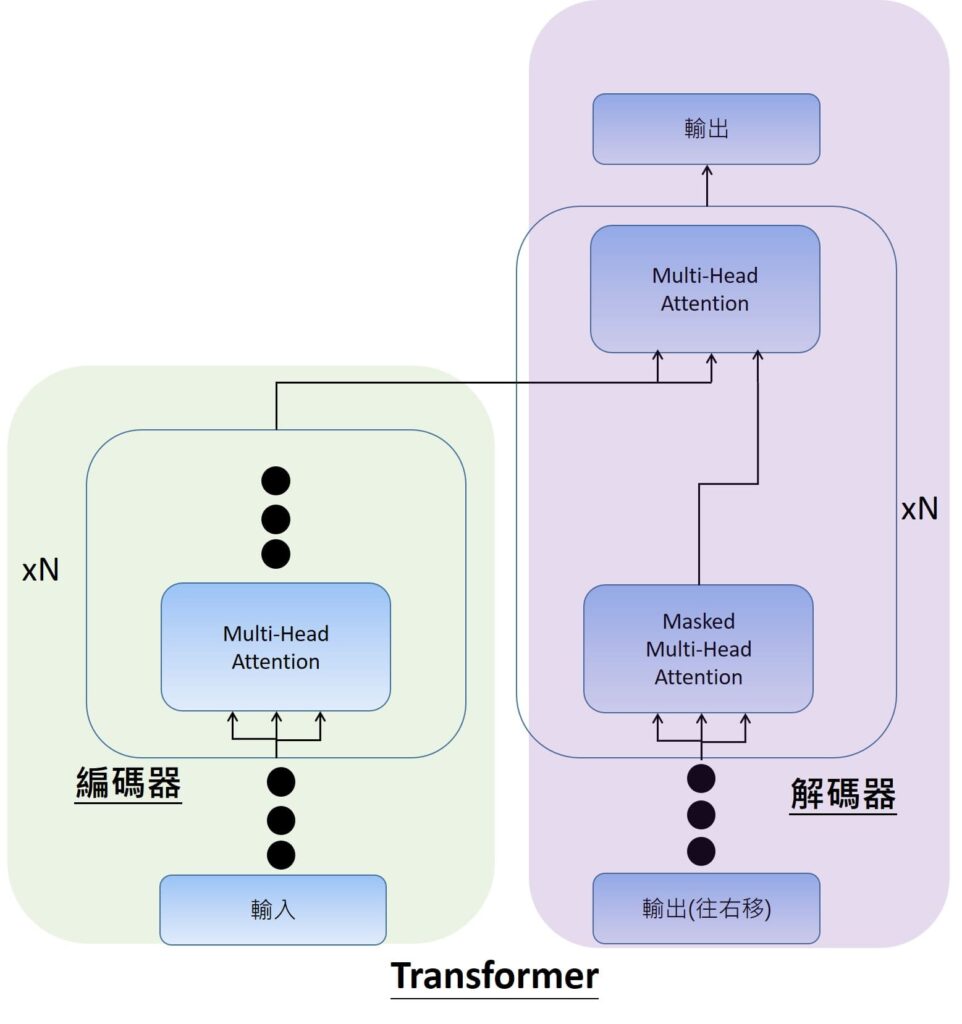
對於BERT模型而言,就只會有綠色方塊的部分,沒有解碼器,全部都是編碼器,在編碼器部分,BERT模型在原版論文裡面,有分成小模型跟大模型互相比較。分別會有N=12個或24個的編碼器。
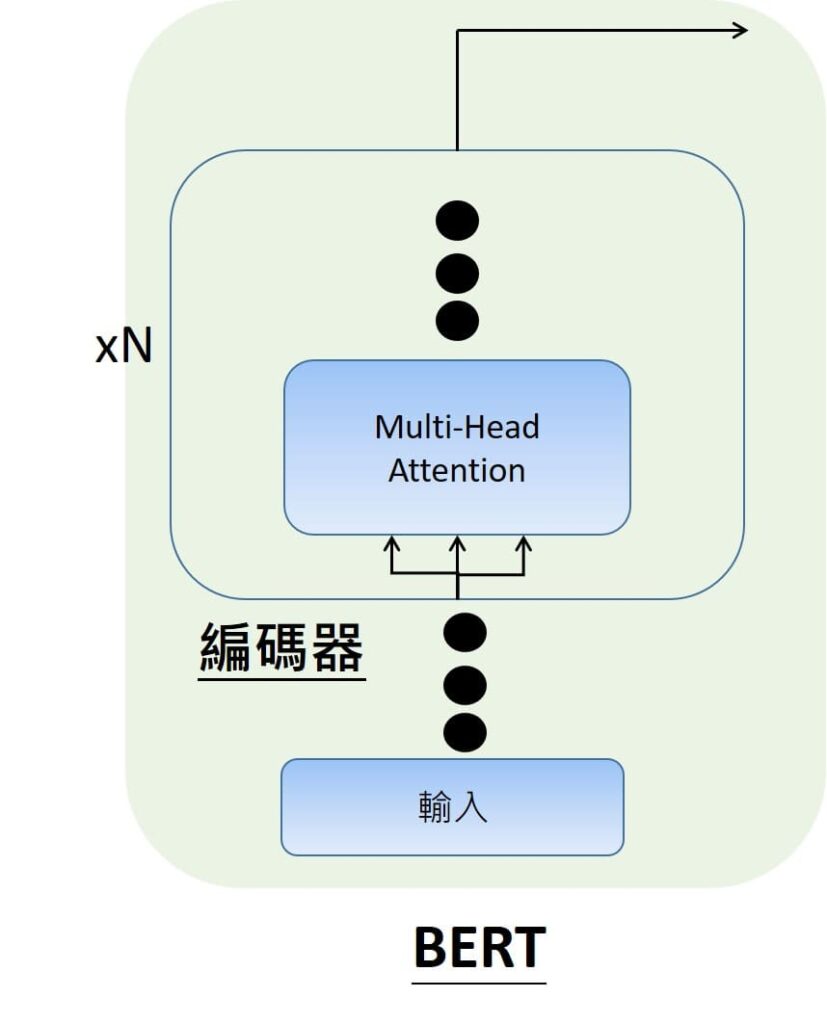
BERT整體架構
輸入
在輸入的部分,一開始就會是輸入文字,可能會有幾句話,像是”大家好,我是李彼德。今天要跟大家分享BERT模型”。接下來就要將文字轉成Token,像是第一個文字就會稱為是CLS,然後接下來會分句子分詞。像是先分句子1.”大家好,我是李彼德“2.”今天要跟大家分享BERT模型。
Token
在句子跟句子中間會有SEP token進行分隔。
然後接下來再將文字分出來,像是”大家“,”好“我””是”“李”…。分成一個一個的字詞。
然後字詞就會轉換成Token數值譬如101,2682等等。
然後會將token轉成embedding。
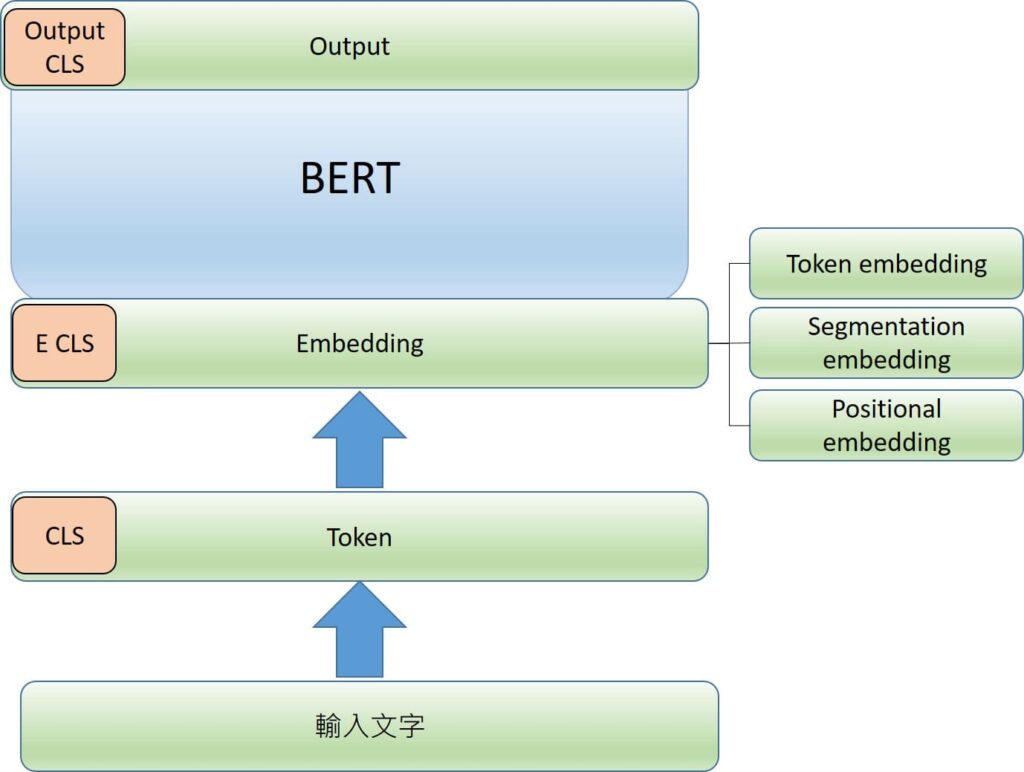
Token embedding
根據Token查表取得Token embedding,變成有向量表示,也就是不是只是單一數值,而是有許多數值組成。像是[0.2,-0.1,0.5….]。
每一個token就會對應到768個數值組成的向量。
Segmentation embedding
說明字詞是落在第一句話還是第二句話,會給一個編碼向量代表是落在哪一句話。
Position emebedding
把字詞先後順序定義,也是會給一個編碼向量代表字詞順序位置。
![然後會將token轉成embedding。
Token embedding
根據Token查表取得Token embedding,變成有向量表示,也就是不是只是單一數值,而是有許多數值組成。像是[0.2,-0.1,0.5....]。
每一個token就會對應到768個數值組成的向量。
Segmentation embeddeding
說明字詞是落在第一句話還是第二句話,會給一個編碼向量代表是落在哪一句話。
Postiion emebedding
把字詞先後順序定義,也是會給一個編碼向量代表字詞順序位置。](https://peterlihouse.com/wp-content/uploads/2025/02/圖片3-1024x563.jpg)
轉換成embedding之後,輸入到BERT當中,也就是先前提到的基於Transformer機制進行計算。
輸出
最終輸出就是輸出embedding,也就是BERT模型語意理解的結果。
第一個Output CLS是綜合所有句子的摘要,而其他output後根據每個詞理解的結果。
BERT如何訓練?
BERT是由Google訓練開發,基於的訓練資料是BooksCorpus許多書籍資料集,以及維基百科。
然後預訓練的任務有兩種,
1.Masked Language Model (MLM):就是隨機選擇將句子的一些詞遮住mask,然後預測被遮住的詞是什麼?讓BERT更可以了解上下文關係。
2.Next Sentence Prediction (NSP):輸入兩個句子,預測第二個句子是否與第一個句子是前後句的關係,藉此讓BERT在句子順序理解上更為準確。
BERT模型應用
Google有將BERT導入搜尋引擎,加強長尾關鍵字搜尋,提升搜尋的準確度。
BERT模型也可在輸出端部分,可以再結合自己定義的模型,像是再接一層分類器,就可以做情感分析的任務,可以判別某句話,或電影影評是正面意涵還是負面意涵。
結論
本篇文章帶您了解BERT模型原理,BERT模型是現在大型語言模型的基石,藉由先了解BERT模型,以及實際操作BERT模型處理自然語言任務,可讓我們更了解現在大型語言模型運作的原理。
想要看更多AI文章,更了解學習脈絡,請參考AI學習路線圖。
最近AI原理文章:
隨機梯度下降法Stochastic Gradient Descent (SGD)
半監督式學習Semi-Supervised Learning
Stable Diffusion原理: 文字生成圖片簡易說明
[類神經網路基礎系列專文]:
1.類神經網路(Deep neural network, DNN)介紹
3.類神經網路—啟動函數介紹(一): 深入解析Relu與Sigmoid函數:如何影響類神經網路的學習效果?
4.類神經網路—啟動函數介紹(二): 回歸 vs. 分類: 線性函數與Tanh函數之原理探索
5.類神經網路—啟動函數介紹(三): 掌握多元分類的核心技術:不可不知的softmax函數原理
6.類神經網路—啟動函數介紹(四): 如何選擇最適當的啟動函數?用一統整表格讓您輕鬆掌握
8.類神經網路—反向傳播法(一): 白話文帶您了解反向傳播法
10.類神經網路—反向傳播法(三): 五步驟帶您了解梯度下降法
11.類神經網路—反向傳播法(四): 揭開反向傳播法神秘面紗
12.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
13.類神經網路—反向傳播法(五): 用等高線圖讓您對學習率更有感
[機器學習基礎系列專文]:
1.機器學習訓練原理大揭秘:六步驟帶您快速了解監督式學習的訓練方法
[類神經網路延伸介紹]:
1.卷積類神經網路(Convolution neural network,CNN)介紹
2.遞迴類神經網路(Recurrent neural network,RNN)介紹
[ChatGPT系列專文]:


![[好書推薦] 從零開始理解深度學習,易讀的圖解AI書籍](https://peterlihouse.com/wp-content/uploads/2025/04/image-150x150.png)